2026
|
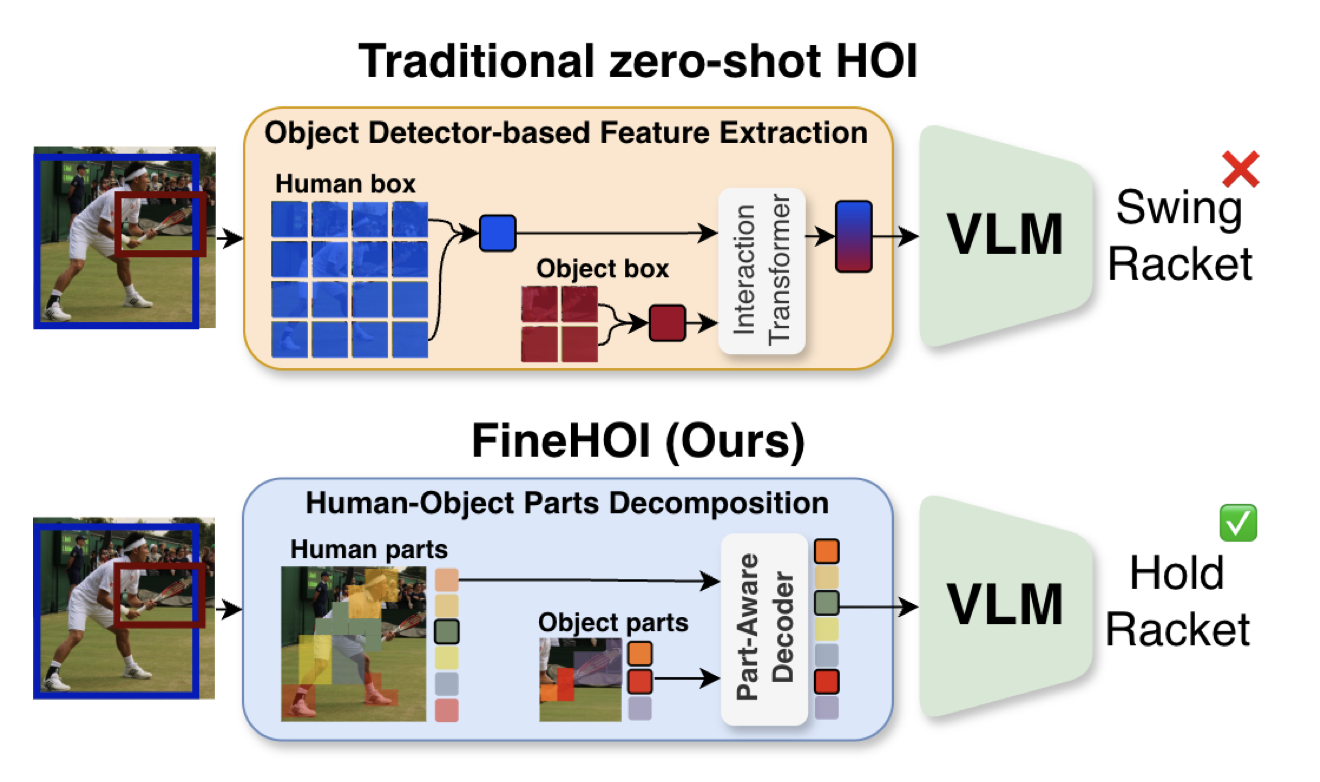 | Francesco Tonini, Lorenzo Vaquero, Mohammad Mahdi Derakhshani, Cees G M Snoek, Elisa Ricci, Cigdem Beyan: FineHOI: Part-Aware Dense Representations for Zero-Shot Human-Object Interaction Detection. In: ACM MM, 2026, (Oral presentation). @inproceedings{ToniniMM2026,
title = {FineHOI: Part-Aware Dense Representations for Zero-Shot Human-Object Interaction Detection},
author = {Francesco Tonini and Lorenzo Vaquero and Mohammad Mahdi Derakhshani and Cees G M Snoek and Elisa Ricci and Cigdem Beyan},
year = {2026},
date = {2026-11-10},
urldate = {2026-11-10},
booktitle = {ACM MM},
note = {Oral presentation},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
|
 | Aritra Bhowmik, Fida Mohammad Thoker, Carlos Hinojosa, Bernard Ghanem, Cees G. M. Snoek: Structured-Noise Masked Modeling for Video, Audio and Beyond. In: ECCV, 2026, (Oral presentation). @inproceedings{bhowmikECCV2026,
title = {Structured-Noise Masked Modeling for Video, Audio and Beyond},
author = {Aritra Bhowmik and Fida Mohammad Thoker and Carlos Hinojosa and Bernard Ghanem and Cees G. M. Snoek},
url = {https://arxiv.org/abs/2503.16311},
year = {2026},
date = {2026-09-08},
urldate = {2026-09-08},
booktitle = {ECCV},
abstract = {Masked modeling has emerged as a powerful self-supervised learning framework, but existing methods largely rely on random masking, disregarding the structural properties of different modalities. In this work, we introduce structured noise-based masking, a simple yet effective approach that naturally aligns with the spatial, temporal, and spectral characteristics of video and audio data. By filtering white noise into distinct color noise distributions, we generate structured masks that preserve modality-specific patterns without requiring handcrafted heuristics or access to the data. Our approach improves the performance of masked video and audio modeling frameworks without any computational overhead. Extensive experiments demonstrate that structured noise masking achieves consistent improvement over random masking for standard and advanced masked modeling methods, highlighting the importance of modality-aware masking strategies for representation learning.},
howpublished = {arXiv:2503.16311},
note = {Oral presentation},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Masked modeling has emerged as a powerful self-supervised learning framework, but existing methods largely rely on random masking, disregarding the structural properties of different modalities. In this work, we introduce structured noise-based masking, a simple yet effective approach that naturally aligns with the spatial, temporal, and spectral characteristics of video and audio data. By filtering white noise into distinct color noise distributions, we generate structured masks that preserve modality-specific patterns without requiring handcrafted heuristics or access to the data. Our approach improves the performance of masked video and audio modeling frameworks without any computational overhead. Extensive experiments demonstrate that structured noise masking achieves consistent improvement over random masking for standard and advanced masked modeling methods, highlighting the importance of modality-aware masking strategies for representation learning. |
 | Sarah Rastegar, Mina Ghadimi Atigh, Pascal Mettes, Yuki M Asano, Cees G. M. Snoek: Fourier Self-Supervision for Fine-Grained Generalized Category Discovery. In: ECCV, 2026. @inproceedings{RastegardECCV2026,
title = {Fourier Self-Supervision for Fine-Grained Generalized Category Discovery},
author = {Sarah Rastegar and Mina Ghadimi Atigh and Pascal Mettes and Yuki M Asano and Cees G. M. Snoek},
url = {https://github.com/SarahRastegar/FourEx},
year = {2026},
date = {2026-09-08},
urldate = {2026-09-08},
booktitle = {ECCV},
abstract = {Generalized Category Discovery aims to recognize known categories while identifying novel ones within unlabeled data. Existing methods, typically based on self-supervision and contrastive learning, often struggle to capture fine-grained distinctions, relying on superficial visual cues rather than the intrinsic attributes humans use for categorization. We introduce Fourier Self-Supervision, that leverages the Fourier transform of images to enhance the discrimination of subtle differences and support the discovery of new categories. Our method employs a dual frequency filtering strategy: a low-pass filter first extracts broad, abstract attributes that capture high-level category information, while a high-pass filter emphasizes fine details such as edges and textures that are essential for fine-grained recognition. Each operates on a dedicated latent space, and their overlapping representations together yield a richer, more complete feature space. This dual-frequency approach not only refines feature extraction to identify novel categories, but also strengthens the model’s discriminative power in fine-grained category discovery. Experiments on multiple fine-grained datasets show that incorporating Fourier Self-Supervision outperforms state-of-the-art methods, even when the number of classes is unknown, demonstrating its effectiveness for Generalized Category Discovery.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Generalized Category Discovery aims to recognize known categories while identifying novel ones within unlabeled data. Existing methods, typically based on self-supervision and contrastive learning, often struggle to capture fine-grained distinctions, relying on superficial visual cues rather than the intrinsic attributes humans use for categorization. We introduce Fourier Self-Supervision, that leverages the Fourier transform of images to enhance the discrimination of subtle differences and support the discovery of new categories. Our method employs a dual frequency filtering strategy: a low-pass filter first extracts broad, abstract attributes that capture high-level category information, while a high-pass filter emphasizes fine details such as edges and textures that are essential for fine-grained recognition. Each operates on a dedicated latent space, and their overlapping representations together yield a richer, more complete feature space. This dual-frequency approach not only refines feature extraction to identify novel categories, but also strengthens the model’s discriminative power in fine-grained category discovery. Experiments on multiple fine-grained datasets show that incorporating Fourier Self-Supervision outperforms state-of-the-art methods, even when the number of classes is unknown, demonstrating its effectiveness for Generalized Category Discovery. |
 | Zhen Zeng, Leijiang Gu, Zhangling Duan, Feng Li, Zenglin Shi, Cees G M Snoek, Meng Wang: Towards Benign Memory Forgetting for Selective Multimodal Large Language Model Unlearning. In: ECCV, 2026. @inproceedings{ZengECCV2026,
title = {Towards Benign Memory Forgetting for Selective Multimodal Large Language Model Unlearning},
author = {Zhen Zeng and Leijiang Gu and Zhangling Duan and Feng Li and Zenglin Shi and Cees G M Snoek and Meng Wang},
url = {https://arxiv.org/abs/2511.20196
https://github.com/zeng-zhen/S-MLLMUn},
year = {2026},
date = {2026-09-08},
urldate = {2026-09-08},
booktitle = {ECCV},
abstract = {Multimodal large language models (MLLMs) can inadvertently memorize privacy-sensitive information during training. While existing unlearning methods can remove such content, they often severely degrade the model's foundational capabilities, such as general image understanding. This critical shortfall motivates our investigation into benign memory forgetting, the precise removal of targeted, privacy-sensitive knowledge while rigorously preserving unrelated capabilities. To pioneer and evaluate progress toward this objective, we introduce S-MLLMUn Bench, the first benchmark designed to jointly and quantitatively assess an unlearning method's efficacy in knowledge erasure and the preservation of image understanding. Furthermore, we propose the Sculpted Memory Forgetting Adapter (SMFA), a new framework that enables benign memory forgetting. SMFA confines forgetting to designated memory regions, maintaining overall model performance. By initially fine-tuning the model to replace sensitive outputs with refusals, SMFA generates a memory forgetting adapter, followed by a retaining anchor-guided masking mechanism that safeguards unrelated knowledge. Extensive experiments on S-MLLMUn Bench demonstrate that existing methods fail to achieve benign forgetting, whereas our proposed SMFA serves as an effective baseline, successfully achieving targeted knowledge erasure without compromising the model's foundational visual capabilities.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Multimodal large language models (MLLMs) can inadvertently memorize privacy-sensitive information during training. While existing unlearning methods can remove such content, they often severely degrade the model's foundational capabilities, such as general image understanding. This critical shortfall motivates our investigation into benign memory forgetting, the precise removal of targeted, privacy-sensitive knowledge while rigorously preserving unrelated capabilities. To pioneer and evaluate progress toward this objective, we introduce S-MLLMUn Bench, the first benchmark designed to jointly and quantitatively assess an unlearning method's efficacy in knowledge erasure and the preservation of image understanding. Furthermore, we propose the Sculpted Memory Forgetting Adapter (SMFA), a new framework that enables benign memory forgetting. SMFA confines forgetting to designated memory regions, maintaining overall model performance. By initially fine-tuning the model to replace sensitive outputs with refusals, SMFA generates a memory forgetting adapter, followed by a retaining anchor-guided masking mechanism that safeguards unrelated knowledge. Extensive experiments on S-MLLMUn Bench demonstrate that existing methods fail to achieve benign forgetting, whereas our proposed SMFA serves as an effective baseline, successfully achieving targeted knowledge erasure without compromising the model's foundational visual capabilities. |
 | Yuqing Lei, Wenbo Lyu, Yingjun Du, Xiantong Zhen, Cees G M Snoek, Ling Shao: See Only When Needed: Context-Aware Attention Intervention for Hallucination-Free LVLMs. In: ECCV, 2026. @inproceedings{LeiECCV2026,
title = {See Only When Needed: Context-Aware Attention Intervention for Hallucination-Free LVLMs},
author = {Yuqing Lei and Wenbo Lyu and Yingjun Du and Xiantong Zhen and Cees G M Snoek and Ling Shao},
url = {https://arxiv.org/abs/2606.29847
https://github.com/Iris1946/CAI},
year = {2026},
date = {2026-09-08},
urldate = {2026-09-08},
booktitle = {ECCV},
abstract = {Large Vision-Language Models (LVLMs) excel at multimodal tasks but remain prone to object hallucinations. Prior training-free remedies often uniformly strengthen visual signals, which may also amplify irrelevant regions and introduce spurious evidence, harming fluency. We propose Context-aware Attention Intervention (CAI), a training-free inference-time mechanism that enforces a see only when needed principle via two-axis selectivity: where to look and when to intervene. At each decoding step, CAI derives token-specific visual relevance from early-layer representations to localize semantically aligned regions, and applies a conservative, entropy- and depth-gated attention tilt only for uncertainty-spiking tokens in deeper layers where visual grounding degrades, leaving confident tokens and irrelevant regions largely unchanged. This targeted intervention strengthens visual grounding while preserving linguistic fluency, and it yields consistent improvements even without contrastive decoding, which remains optional as an auxiliary bias-suppression module. Extensive experiments across multiple LVLM backbones and benchmarks show that CAI achieves state-of-the-art hallucination mitigation, and our analysis characterizes CAI as a KL-minimal attention reweighting with bounded interference under inactive gates or small tilts. },
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Large Vision-Language Models (LVLMs) excel at multimodal tasks but remain prone to object hallucinations. Prior training-free remedies often uniformly strengthen visual signals, which may also amplify irrelevant regions and introduce spurious evidence, harming fluency. We propose Context-aware Attention Intervention (CAI), a training-free inference-time mechanism that enforces a see only when needed principle via two-axis selectivity: where to look and when to intervene. At each decoding step, CAI derives token-specific visual relevance from early-layer representations to localize semantically aligned regions, and applies a conservative, entropy- and depth-gated attention tilt only for uncertainty-spiking tokens in deeper layers where visual grounding degrades, leaving confident tokens and irrelevant regions largely unchanged. This targeted intervention strengthens visual grounding while preserving linguistic fluency, and it yields consistent improvements even without contrastive decoding, which remains optional as an auxiliary bias-suppression module. Extensive experiments across multiple LVLM backbones and benchmarks show that CAI achieves state-of-the-art hallucination mitigation, and our analysis characterizes CAI as a KL-minimal attention reweighting with bounded interference under inactive gates or small tilts. |
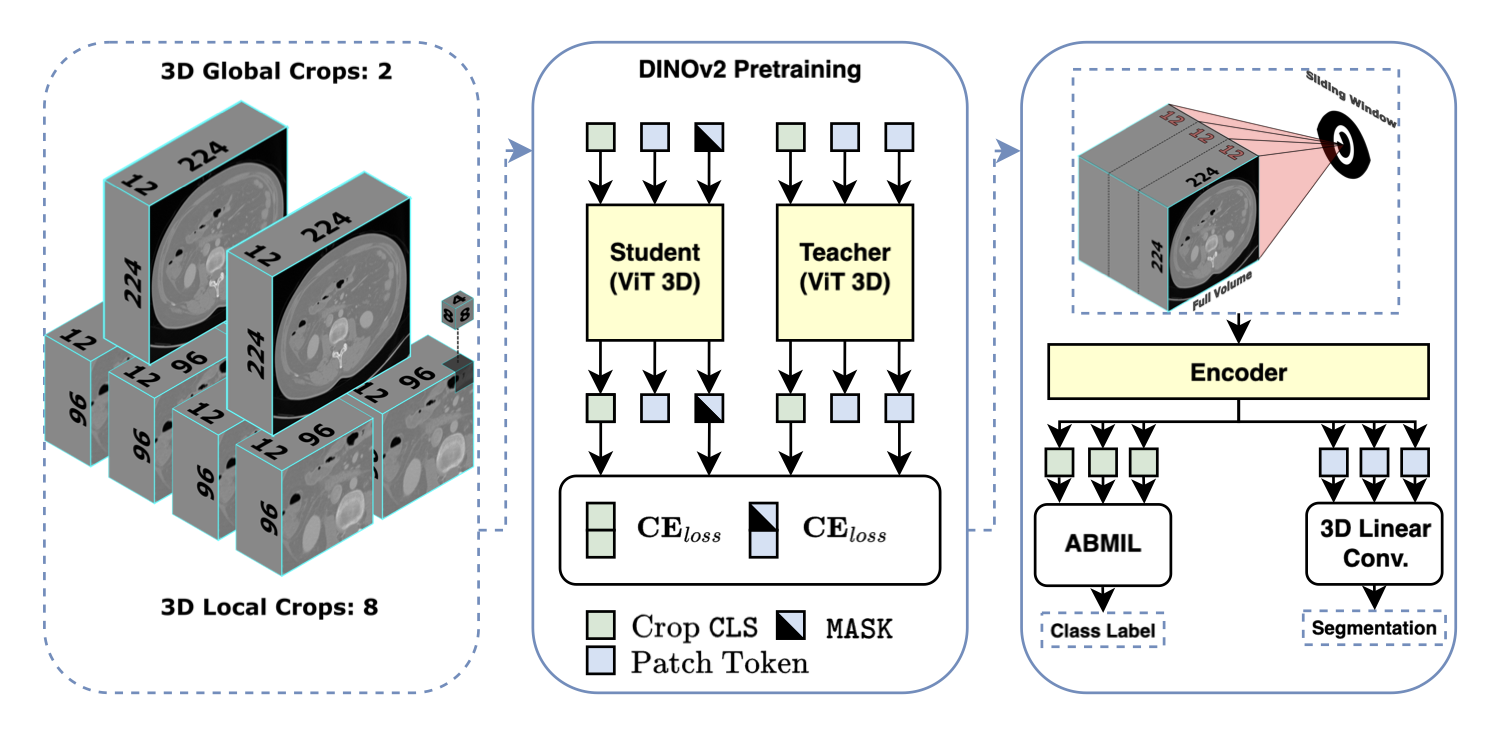 | Tim Veenboer, George Yiasemis, Eric Marcus, Vivien van Veldhuizen, Cees G M Snoek, Jonas Teuwen, Kevin B. W. Groot Lipman: TAP-CT: 3D Task-Agnostic Pretraining of Computed Tomography Foundation Models. In: MIDL, 2026. @inproceedings{VeenboerMIDL2026,
title = {TAP-CT: 3D Task-Agnostic Pretraining of Computed Tomography Foundation Models},
author = {Tim Veenboer and George Yiasemis and Eric Marcus and Vivien van Veldhuizen and Cees G M Snoek and Jonas Teuwen and Kevin B. W. Groot Lipman},
url = {https://huggingface.co/fomofo/tap-ct-b-3d
https://arxiv.org/abs/2512.00872},
year = {2026},
date = {2026-07-08},
urldate = {2025-11-30},
booktitle = {MIDL},
abstract = {Existing foundation models (FMs) in the medical domain often require extensive fine-tuning or rely on training resource-intensive decoders, while many existing encoders are pretrained with objectives biased toward specific tasks. This illustrates a need for a strong, task-agnostic foundation model that requires minimal fine-tuning beyond feature extraction. In this work, we introduce a suite of task-agnostic pretraining of CT foundation models (TAP-CT): a simple yet effective adaptation of Vision Transformers (ViTs) and DINOv2 for volumetric data, enabling scalable self-supervised pretraining directly on 3D CT volumes. Our approach incorporates targeted modifications to patch embeddings, positional encodings, and volumetric augmentations, making the architecture depth-aware while preserving the simplicity of the underlying architectures. We show that large-scale 3D pretraining on an extensive in-house CT dataset (105K volumes) yields stable, robust frozen representations that generalize strongly across downstream tasks. To promote transparency and reproducibility, and to establish a powerful, low-resource baseline for future research in medical imaging, we will release all pretrained models, experimental configurations, and downstream benchmark code.},
howpublished = {arXiv:2512.00872},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Existing foundation models (FMs) in the medical domain often require extensive fine-tuning or rely on training resource-intensive decoders, while many existing encoders are pretrained with objectives biased toward specific tasks. This illustrates a need for a strong, task-agnostic foundation model that requires minimal fine-tuning beyond feature extraction. In this work, we introduce a suite of task-agnostic pretraining of CT foundation models (TAP-CT): a simple yet effective adaptation of Vision Transformers (ViTs) and DINOv2 for volumetric data, enabling scalable self-supervised pretraining directly on 3D CT volumes. Our approach incorporates targeted modifications to patch embeddings, positional encodings, and volumetric augmentations, making the architecture depth-aware while preserving the simplicity of the underlying architectures. We show that large-scale 3D pretraining on an extensive in-house CT dataset (105K volumes) yields stable, robust frozen representations that generalize strongly across downstream tasks. To promote transparency and reproducibility, and to establish a powerful, low-resource baseline for future research in medical imaging, we will release all pretrained models, experimental configurations, and downstream benchmark code. |
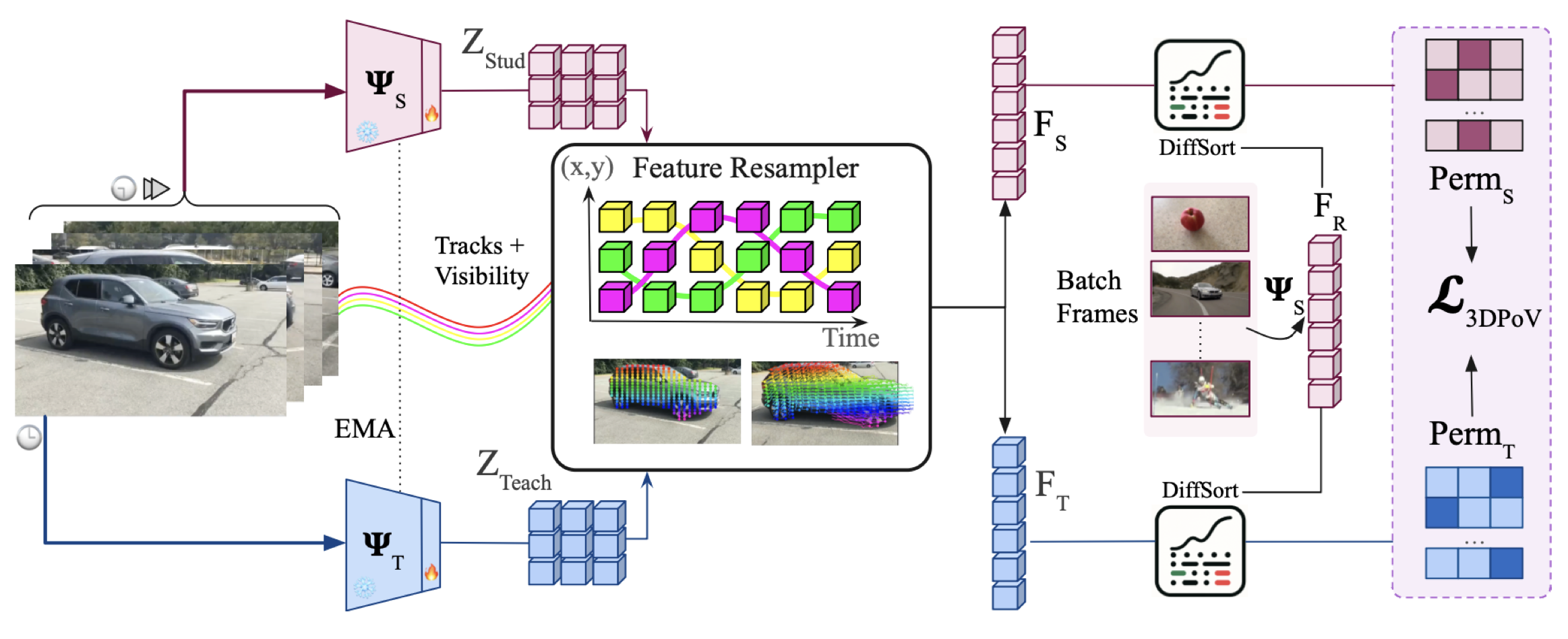 | Ioana Simion, Mohammadreza Salehi, Shashanka Venkataramanan, Cees G M Snoek, Yuki M Asano: 3DPoV: Improving 3D understanding via Patch Ordering on Videos. In: ICML, 2026. @inproceedings{SimionICML2026,
title = {3DPoV: Improving 3D understanding via Patch Ordering on Videos},
author = {Ioana Simion and Mohammadreza Salehi and Shashanka Venkataramanan and Cees G M Snoek and Yuki M Asano},
year = {2026},
date = {2026-07-06},
urldate = {2026-07-06},
booktitle = {ICML},
abstract = {Visual foundation models have achieved remarkable progress in scale and versatility, yet understanding the 3D world remains a fundamental challenge. While 2D images contain cues about 3D structure that humans readily interpret, deep models often fail to exploit them, underperforming on tasks such as multiview semantic consistency--crucial for applications including robotics and autonomous driving. We propose a self-supervised approach to enhance the 3D understanding of vision foundation models by (i) introducing a temporal nearest-neighbor consistency loss that finds corresponding points across video frames and enforces consistency between their nearest neighbors, (ii) incorporating reference-guided ordering that requires patch-level features to be not only expressive but also consistently aligned, and (iii) constructing a mixture of video datasets tailored to these objectives, thereby leveraging rich 3D information. Our method, 3DPoV, achieves state-of-the-art performance in keypoint matching under viewpoint variation, as well as in depth and surface normal estimation, and consistently improves a diverse set of backbones, including DINOv3.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Visual foundation models have achieved remarkable progress in scale and versatility, yet understanding the 3D world remains a fundamental challenge. While 2D images contain cues about 3D structure that humans readily interpret, deep models often fail to exploit them, underperforming on tasks such as multiview semantic consistency--crucial for applications including robotics and autonomous driving. We propose a self-supervised approach to enhance the 3D understanding of vision foundation models by (i) introducing a temporal nearest-neighbor consistency loss that finds corresponding points across video frames and enforces consistency between their nearest neighbors, (ii) incorporating reference-guided ordering that requires patch-level features to be not only expressive but also consistently aligned, and (iii) constructing a mixture of video datasets tailored to these objectives, thereby leveraging rich 3D information. Our method, 3DPoV, achieves state-of-the-art performance in keypoint matching under viewpoint variation, as well as in depth and surface normal estimation, and consistently improves a diverse set of backbones, including DINOv3. |
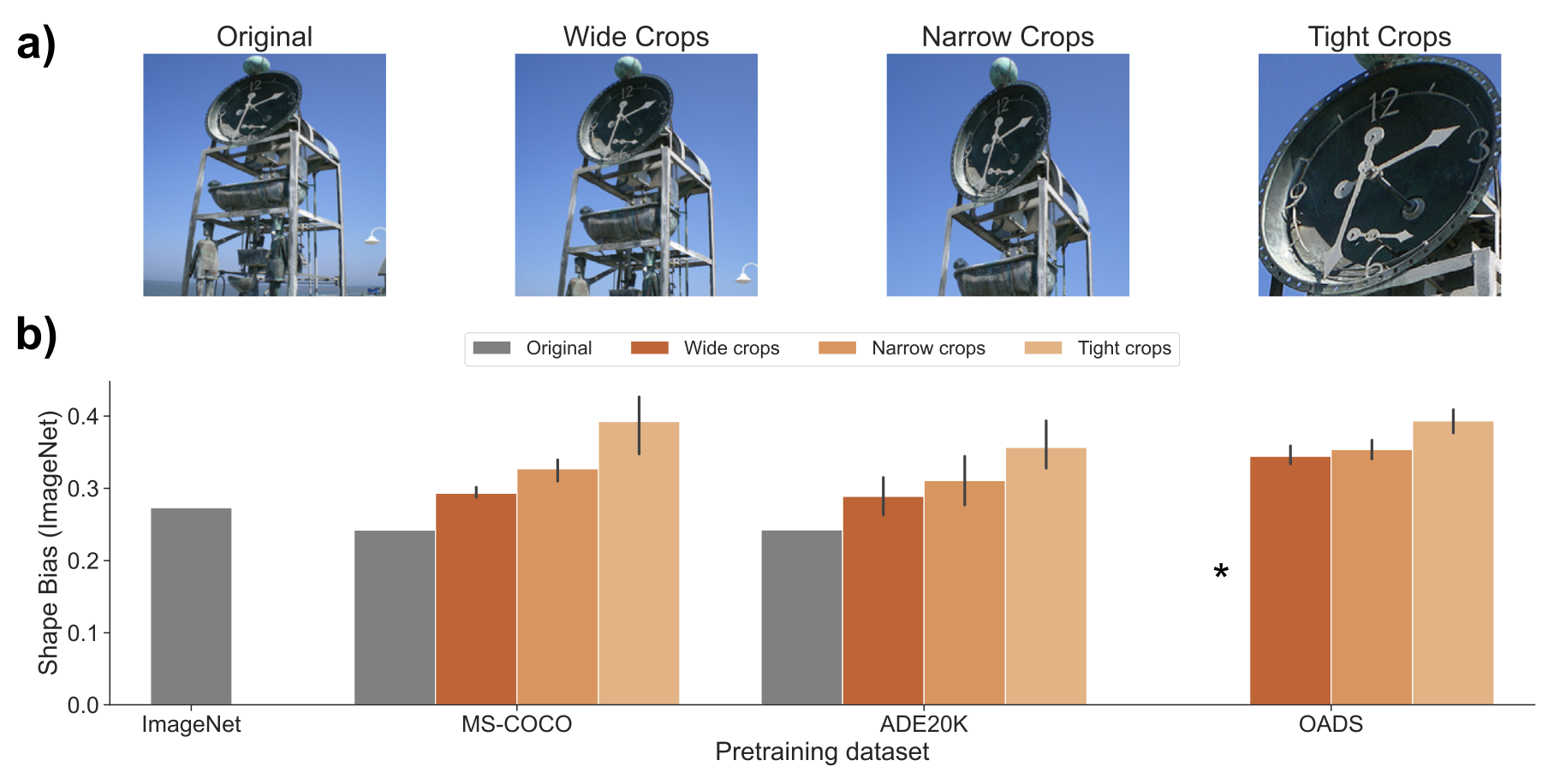 | Niklas Müller, Cees G M Snoek, Iris I A Groen, H. Steven Scholte: Object-Zoomed Training of Convolutional Neural Networks Inspired by Toddler Development Improves Shape Bias. In: Connection Science, 2026, (In press). @article{MullerCCOS2026,
title = {Object-Zoomed Training of Convolutional Neural Networks Inspired by Toddler Development Improves Shape Bias},
author = {Niklas Müller and Cees G M Snoek and Iris I A Groen and H. Steven Scholte},
url = {https://www.biorxiv.org/content/10.1101/2024.05.30.595526v2
https://www.tandfonline.com/doi/full/10.1080/09540091.2026.2694256},
year = {2026},
date = {2026-06-23},
urldate = {2026-06-23},
journal = {Connection Science},
abstract = {Convolutional Neural Networks (CNNs) surpass human-level performance on visual object recognition and detection, but their behavior still differs from human behavior in important ways. One prominent example is that CNNs trained on ImageNet exhibit an image texture bias, while humans exhibit a strong bias toward object shape. Although CNN shape bias can be increased in various ways, e.g., using data augmentation or additional training techniques, it remains unclear what causes the strong discrepancy between human and CNN object recognition strategies. Developmental research suggests that one factor driving human shape bias is that during early childhood, toddlers tend to fill their field-of-view with close-up objects. Here, we operationalize this close-up as a zoom-in on objects during CNN training which we show increases shape bias without any additional training or data augmentation. We provide further evidence for the advantage of closeup object vision by systematically manipulating the background-object ratio during CNN training, and demonstrate a strong (inverse) correlation with shape bias. Moreover, zooming-in on objects, thereby more closely emulating child vision, not only increases shape bias but also concurrently aligns classification accuracy and shape bias between humans and CNNs. Finally, we achieve a near human-like shape bias when using a developmentally-inspired background-object ratio for training and shape bias assessment. In sum, from a simple adjustment to common image datasets - zooming-in on objects - human-like shape bias can emerge. These results suggest that taking inspiration from human learning strategies is a promising avenue for building human-aligned, efficient, and more robust vision CNNs.},
note = {In press},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Convolutional Neural Networks (CNNs) surpass human-level performance on visual object recognition and detection, but their behavior still differs from human behavior in important ways. One prominent example is that CNNs trained on ImageNet exhibit an image texture bias, while humans exhibit a strong bias toward object shape. Although CNN shape bias can be increased in various ways, e.g., using data augmentation or additional training techniques, it remains unclear what causes the strong discrepancy between human and CNN object recognition strategies. Developmental research suggests that one factor driving human shape bias is that during early childhood, toddlers tend to fill their field-of-view with close-up objects. Here, we operationalize this close-up as a zoom-in on objects during CNN training which we show increases shape bias without any additional training or data augmentation. We provide further evidence for the advantage of closeup object vision by systematically manipulating the background-object ratio during CNN training, and demonstrate a strong (inverse) correlation with shape bias. Moreover, zooming-in on objects, thereby more closely emulating child vision, not only increases shape bias but also concurrently aligns classification accuracy and shape bias between humans and CNNs. Finally, we achieve a near human-like shape bias when using a developmentally-inspired background-object ratio for training and shape bias assessment. In sum, from a simple adjustment to common image datasets - zooming-in on objects - human-like shape bias can emerge. These results suggest that taking inspiration from human learning strategies is a promising avenue for building human-aligned, efficient, and more robust vision CNNs. |
 | Ziqi Wang, Chang Che, Qi Wang, Hui Ma, Zenglin Shi, Cees G M Snoek, Meng Wang: Harmonious Parameter Adaptation in Continual Visual Instruction Tuning for Safety-Aligned MLLMs. In: CVPR, 2026. @inproceedings{WangCVPR2026,
title = {Harmonious Parameter Adaptation in Continual Visual Instruction Tuning for Safety-Aligned MLLMs},
author = {Ziqi Wang and Chang Che and Qi Wang and Hui Ma and Zenglin Shi and Cees G M Snoek and Meng Wang},
url = {https://arxiv.org/abs/2511.20158},
year = {2026},
date = {2026-06-03},
booktitle = {CVPR},
abstract = {While continual visual instruction tuning (CVIT) has shown promise in adapting multimodal large language models (MLLMs), existing studies predominantly focus on models without safety alignment. This critical oversight ignores the fact that real-world MLLMs inherently require such mechanisms to mitigate potential risks. In this work, we shift our focus to CVIT for safety-aligned MLLMs and observe that during continual adaptation, the model not only suffers from task forgetting but also exhibits degradation in its safety. Achieving a harmonious balance between safety and task performance remains a crucial challenge. To address this, we propose Harmonious Parameter Adaptation (HPA), a post-training framework composed of focusing-based parameter partition, harmoniously balanced parameter selection, and orthogonal parameter adjustment. Specifically, HPA partitions parameters into two types based on their focus on safety or task performance, and selects the focused ones to preserve from a balanced perspective. In addition, HPA imposes orthogonality constraints on parameter updates to further alleviate catastrophic forgetting. Extensive experiments on the CVIT benchmark and safety evaluation datasets demonstrate that HPA better maintains high safety and mitigates forgetting than existing baselines.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
While continual visual instruction tuning (CVIT) has shown promise in adapting multimodal large language models (MLLMs), existing studies predominantly focus on models without safety alignment. This critical oversight ignores the fact that real-world MLLMs inherently require such mechanisms to mitigate potential risks. In this work, we shift our focus to CVIT for safety-aligned MLLMs and observe that during continual adaptation, the model not only suffers from task forgetting but also exhibits degradation in its safety. Achieving a harmonious balance between safety and task performance remains a crucial challenge. To address this, we propose Harmonious Parameter Adaptation (HPA), a post-training framework composed of focusing-based parameter partition, harmoniously balanced parameter selection, and orthogonal parameter adjustment. Specifically, HPA partitions parameters into two types based on their focus on safety or task performance, and selects the focused ones to preserve from a balanced perspective. In addition, HPA imposes orthogonality constraints on parameter updates to further alleviate catastrophic forgetting. Extensive experiments on the CVIT benchmark and safety evaluation datasets demonstrate that HPA better maintains high safety and mitigates forgetting than existing baselines. |
 | Wenfang Sun, Hao Chen, Yingjun Du, Yefeng Zheng, Cees G M Snoek: RegionReasoner: Region-Grounded Multi-Round Visual Reasoning. In: ICLR, 2026. @inproceedings{SunICLR2026,
title = {RegionReasoner: Region-Grounded Multi-Round Visual Reasoning},
author = {Wenfang Sun and Hao Chen and Yingjun Du and Yefeng Zheng and Cees G M Snoek},
url = {https://arxiv.org/abs/2602.03733
https://github.com/lmsdss/RegionReasoner},
year = {2026},
date = {2026-04-24},
urldate = {2026-04-24},
booktitle = {ICLR},
abstract = {Large vision-language models have achieved remarkable progress in visual reasoning, yet most existing systems rely on single-step or text-only reasoning, limiting their ability to iteratively refine understanding across multiple visual contexts. To address this limitation, we introduce a new multi-round visual reasoning benchmark with training and test sets spanning both detection and segmentation tasks, enabling systematic evaluation under iterative reasoning scenarios. We further propose RegionReasoner, a reinforcement learning framework that enforces grounded reasoning by requiring each reasoning trace to explicitly cite the corresponding reference bounding boxes, while maintaining semantic coherence via a global-local consistency reward. This reward extracts key objects and nouns from both global scene captions and region-level captions, aligning them with the reasoning trace to ensure consistency across reasoning steps. RegionReasoner is optimized with structured rewards combining grounding fidelity and global-local semantic alignment. Experiments on detection and segmentation tasks show that RegionReasoner-7B, together with our newly introduced benchmark RegionDial-Bench, considerably improves multi-round reasoning accuracy, spatial grounding precision, and global-local consistency, establishing a strong baseline for this emerging research direction.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Large vision-language models have achieved remarkable progress in visual reasoning, yet most existing systems rely on single-step or text-only reasoning, limiting their ability to iteratively refine understanding across multiple visual contexts. To address this limitation, we introduce a new multi-round visual reasoning benchmark with training and test sets spanning both detection and segmentation tasks, enabling systematic evaluation under iterative reasoning scenarios. We further propose RegionReasoner, a reinforcement learning framework that enforces grounded reasoning by requiring each reasoning trace to explicitly cite the corresponding reference bounding boxes, while maintaining semantic coherence via a global-local consistency reward. This reward extracts key objects and nouns from both global scene captions and region-level captions, aligning them with the reasoning trace to ensure consistency across reasoning steps. RegionReasoner is optimized with structured rewards combining grounding fidelity and global-local semantic alignment. Experiments on detection and segmentation tasks show that RegionReasoner-7B, together with our newly introduced benchmark RegionDial-Bench, considerably improves multi-round reasoning accuracy, spatial grounding precision, and global-local consistency, establishing a strong baseline for this emerging research direction. |
 | Răzvan-Andrei Matişan, Vincent Tao Hu, Grigory Bartosh, Björn Ommer, Cees G M Snoek, Max Welling, Jan-Willem van de Meent, Mohammad Mahdi Derakhshani, Floor Eijkelboom: Purrception: Variational Flow Matching for Vector-Quantized Image Generation. In: ICLR, 2026. @inproceedings{MatisanICLR2026,
title = {Purrception: Variational Flow Matching for Vector-Quantized Image Generation},
author = {Răzvan-Andrei Matişan and Vincent Tao Hu and Grigory Bartosh and Björn Ommer and Cees G M Snoek and Max Welling and Jan-Willem van de Meent and Mohammad Mahdi Derakhshani and Floor Eijkelboom},
url = {https://arxiv.org/abs/2510.01478},
year = {2026},
date = {2026-04-23},
urldate = {2025-10-01},
booktitle = {ICLR},
abstract = {We introduce Purrception, a variational flow matching approach for vector-quantized image generation that provides explicit categorical supervision while maintaining continuous transport dynamics. Our method adapts Variational Flow Matching to vector-quantized latents by learning categorical posteriors over codebook indices while computing velocity fields in the continuous embedding space. This combines the geometric awareness of continuous methods with the discrete supervision of categorical approaches, enabling uncertainty quantification over plausible codes and temperature-controlled generation. We evaluate Purrception on ImageNet-1k 256x256 generation. Training converges faster than both continuous flow matching and discrete flow matching baselines while achieving competitive FID scores with state-of-the-art models. This demonstrates that Variational Flow Matching can effectively bridge continuous transport and discrete supervision for improved training efficiency in image generation.},
howpublished = {arXiv:2510.01478},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
We introduce Purrception, a variational flow matching approach for vector-quantized image generation that provides explicit categorical supervision while maintaining continuous transport dynamics. Our method adapts Variational Flow Matching to vector-quantized latents by learning categorical posteriors over codebook indices while computing velocity fields in the continuous embedding space. This combines the geometric awareness of continuous methods with the discrete supervision of categorical approaches, enabling uncertainty quantification over plausible codes and temperature-controlled generation. We evaluate Purrception on ImageNet-1k 256x256 generation. Training converges faster than both continuous flow matching and discrete flow matching baselines while achieving competitive FID scores with state-of-the-art models. This demonstrates that Variational Flow Matching can effectively bridge continuous transport and discrete supervision for improved training efficiency in image generation. |
 | Aritra Bhowmik, Denis Korzhenkov, Cees G M Snoek, Amirhossein Habibian, Mohsen Ghafoorian: MoAlign: Motion-Centric Representation Alignment for Video Diffusion Models. In: ICLR, 2026. @inproceedings{BhowmikICLR2026,
title = {MoAlign: Motion-Centric Representation Alignment for Video Diffusion Models},
author = {Aritra Bhowmik and Denis Korzhenkov and Cees G M Snoek and Amirhossein Habibian and Mohsen Ghafoorian},
url = {https://arxiv.org/abs/2510.19022},
year = {2026},
date = {2026-04-23},
urldate = {2025-10-21},
booktitle = {ICLR},
abstract = {Text-to-video diffusion models have enabled high-quality video synthesis, yet often fail to generate temporally coherent and physically plausible motion. A key reason is the models' insufficient understanding of complex motions that natural videos often entail. Recent works tackle this problem by aligning diffusion model features with those from pretrained video encoders. However, these encoders mix video appearance and dynamics into entangled features, limiting the benefit of such alignment. In this paper, we propose a motion-centric alignment framework that learns a disentangled motion subspace from a pretrained video encoder. This subspace is optimized to predict ground-truth optical flow, ensuring it captures true motion dynamics. We then align the latent features of a text-to-video diffusion model to this new subspace, enabling the generative model to internalize motion knowledge and generate more plausible videos. Our method improves the physical commonsense in a state-of-the-art video diffusion model, while preserving adherence to textual prompts, as evidenced by empirical evaluations on VideoPhy, VideoPhy2, VBench, and VBench-2.0, along with a user study.},
howpublished = {arXiv:2510.19022},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Text-to-video diffusion models have enabled high-quality video synthesis, yet often fail to generate temporally coherent and physically plausible motion. A key reason is the models' insufficient understanding of complex motions that natural videos often entail. Recent works tackle this problem by aligning diffusion model features with those from pretrained video encoders. However, these encoders mix video appearance and dynamics into entangled features, limiting the benefit of such alignment. In this paper, we propose a motion-centric alignment framework that learns a disentangled motion subspace from a pretrained video encoder. This subspace is optimized to predict ground-truth optical flow, ensuring it captures true motion dynamics. We then align the latent features of a text-to-video diffusion model to this new subspace, enabling the generative model to internalize motion knowledge and generate more plausible videos. Our method improves the physical commonsense in a state-of-the-art video diffusion model, while preserving adherence to textual prompts, as evidenced by empirical evaluations on VideoPhy, VideoPhy2, VBench, and VBench-2.0, along with a user study. |
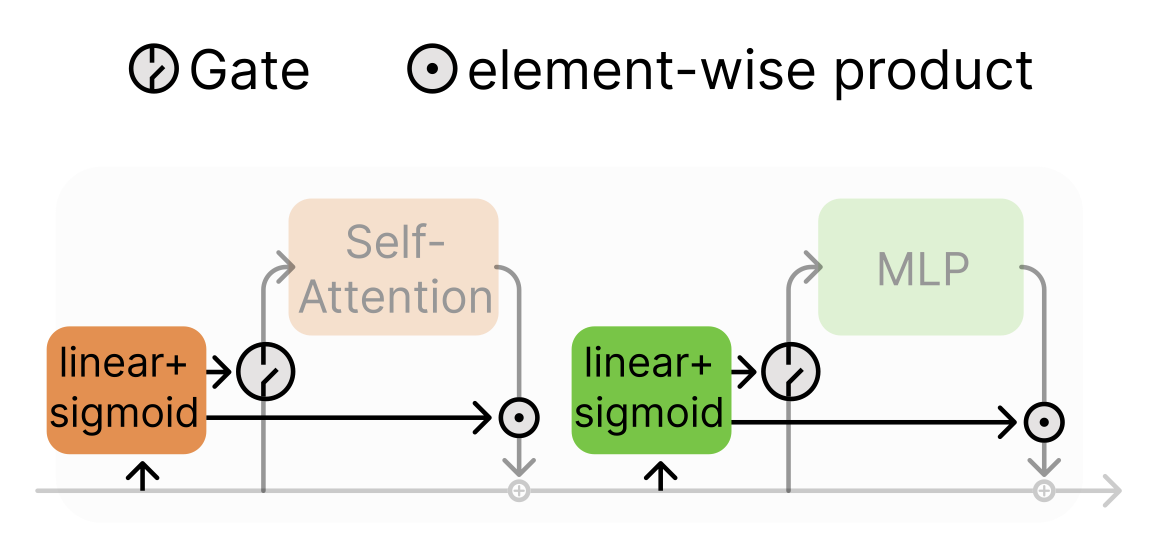 | Filipe Laitenberger, Dawid Jan Kopiczko, Cees G M Snoek, Yuki M Asano: What Layers When: Learning to Skip Compute in LLMs with Residual Gates. In: ICLR, 2026. @inproceedings{LaitenbergerICLR2026,
title = {What Layers When: Learning to Skip Compute in LLMs with Residual Gates},
author = {Filipe Laitenberger and Dawid Jan Kopiczko and Cees G M Snoek and Yuki M Asano},
url = {https://arxiv.org/abs/2510.13876},
year = {2026},
date = {2026-04-23},
urldate = {2026-04-23},
booktitle = {ICLR},
abstract = {We introduce GateSkip, a simple residual-stream gating mechanism that enables token-wise layer skipping in decoder-only LMs. Each Attention/MLP branch is equipped with a sigmoid-linear gate that condenses the branch's output before it re-enters the residual stream. During inference we rank tokens by the gate values and skip low-importance ones using a per-layer budget. While early-exit or router-based Mixture-of-Depths models are known to be unstable and need extensive retraining, our smooth, differentiable gates fine-tune stably on top of pretrained models. On long-form reasoning, we save up to 15% compute while retaining over 90% of baseline accuracy. For increasingly larger models, this tradeoff improves drastically. On instruction-tuned models we see accuracy gains at full compute and match baseline quality near 50% savings. The learned gates give insight into transformer information flow (e.g., BOS tokens act as anchors), and the method combines easily with quantization, pruning, and self-speculative decoding.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
We introduce GateSkip, a simple residual-stream gating mechanism that enables token-wise layer skipping in decoder-only LMs. Each Attention/MLP branch is equipped with a sigmoid-linear gate that condenses the branch's output before it re-enters the residual stream. During inference we rank tokens by the gate values and skip low-importance ones using a per-layer budget. While early-exit or router-based Mixture-of-Depths models are known to be unstable and need extensive retraining, our smooth, differentiable gates fine-tune stably on top of pretrained models. On long-form reasoning, we save up to 15% compute while retaining over 90% of baseline accuracy. For increasingly larger models, this tradeoff improves drastically. On instruction-tuned models we see accuracy gains at full compute and match baseline quality near 50% savings. The learned gates give insight into transformer information flow (e.g., BOS tokens act as anchors), and the method combines easily with quantization, pruning, and self-speculative decoding. |
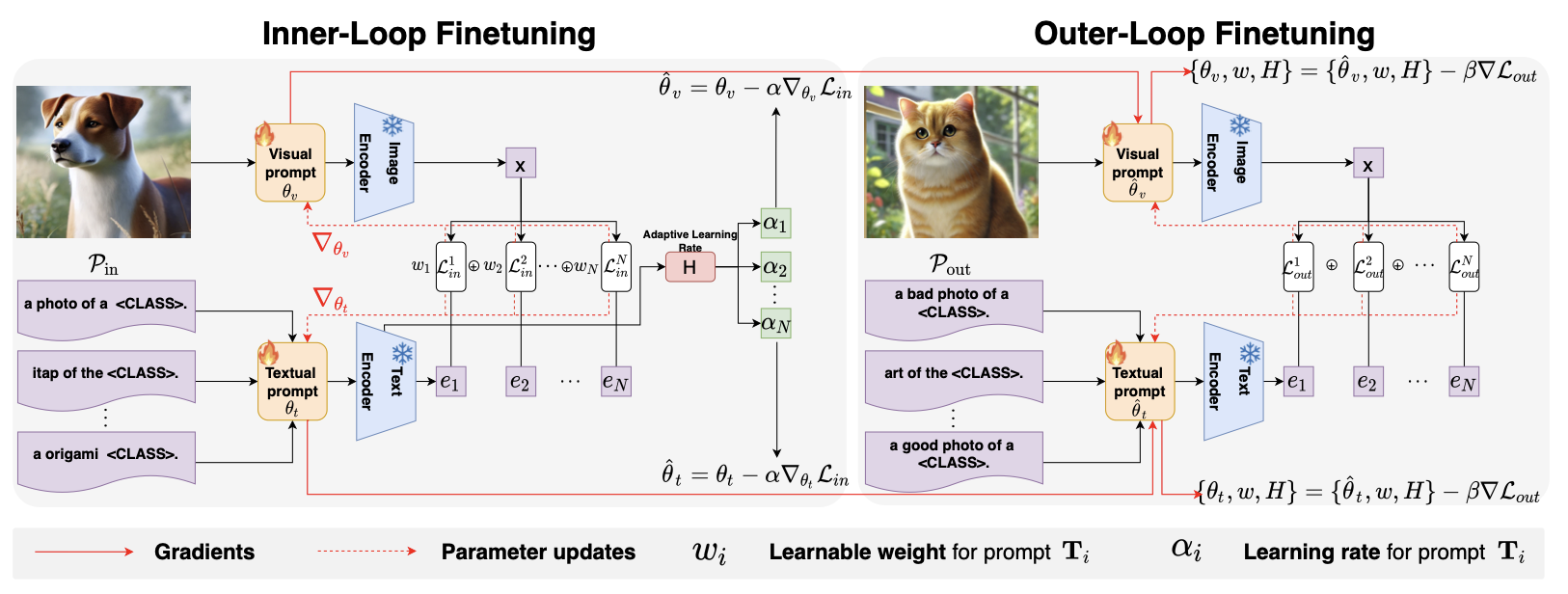 | Haohui Liang, Runlin Huang, Yingjun Du, Yujia Hu, Weifeng Su, Cees G M Snoek: Prompt-Robust Vision-Language Models via Meta-Finetuning. In: ICLR, 2026. @inproceedings{LiangICLR2026,
title = {Prompt-Robust Vision-Language Models via Meta-Finetuning},
author = {Haohui Liang and Runlin Huang and Yingjun Du and Yujia Hu and Weifeng Su and Cees G M Snoek},
url = {https://openreview.net/forum?id=3wZ6IIwPJq},
year = {2026},
date = {2026-04-23},
urldate = {2026-04-23},
booktitle = {ICLR},
abstract = {Vision-language models (VLMs) have demonstrated remarkable generalization across diverse tasks by leveraging large-scale image-text pretraining. However, their performance is notoriously unstable under variations in natural language prompts, posing a considerable challenge for reliable real-world deployment. To address this prompt sensitivity, we propose Promise, a meta-learning framework for prompt-Robust vision-language models via meta-finetuning, which explicitly learns to generalize across diverse prompt formulations. Our method operates in a dual-loop meta-finetuning setting: the inner loop adapts token embeddings based on a set of varied prompts, while the outer loop optimizes for generalization on unseen prompt variants. To further improve robustness, we introduce an adaptive prompt weighting mechanism that dynamically emphasizes more generalizable prompts and a token-specific learning rate module that fine-tunes individual prompt tokens based on contextual importance. We further establish that Promise’s weighted and preconditioned inner update provably (i) yields a one-step decrease of the outer empirical risk together with a contraction of across-prompt sensitivity, and (ii) tightens a data-dependent generalization bound evaluated at the post-inner initialization. Across 15 benchmarks spanning base-to-novel generalization, cross-dataset transfer, and domain shift, our approach consistently reduces prompt sensitivity and improves performance stability over existing prompt learning methods.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Vision-language models (VLMs) have demonstrated remarkable generalization across diverse tasks by leveraging large-scale image-text pretraining. However, their performance is notoriously unstable under variations in natural language prompts, posing a considerable challenge for reliable real-world deployment. To address this prompt sensitivity, we propose Promise, a meta-learning framework for prompt-Robust vision-language models via meta-finetuning, which explicitly learns to generalize across diverse prompt formulations. Our method operates in a dual-loop meta-finetuning setting: the inner loop adapts token embeddings based on a set of varied prompts, while the outer loop optimizes for generalization on unseen prompt variants. To further improve robustness, we introduce an adaptive prompt weighting mechanism that dynamically emphasizes more generalizable prompts and a token-specific learning rate module that fine-tunes individual prompt tokens based on contextual importance. We further establish that Promise’s weighted and preconditioned inner update provably (i) yields a one-step decrease of the outer empirical risk together with a contraction of across-prompt sensitivity, and (ii) tightens a data-dependent generalization bound evaluated at the post-inner initialization. Across 15 benchmarks spanning base-to-novel generalization, cross-dataset transfer, and domain shift, our approach consistently reduces prompt sensitivity and improves performance stability over existing prompt learning methods. |
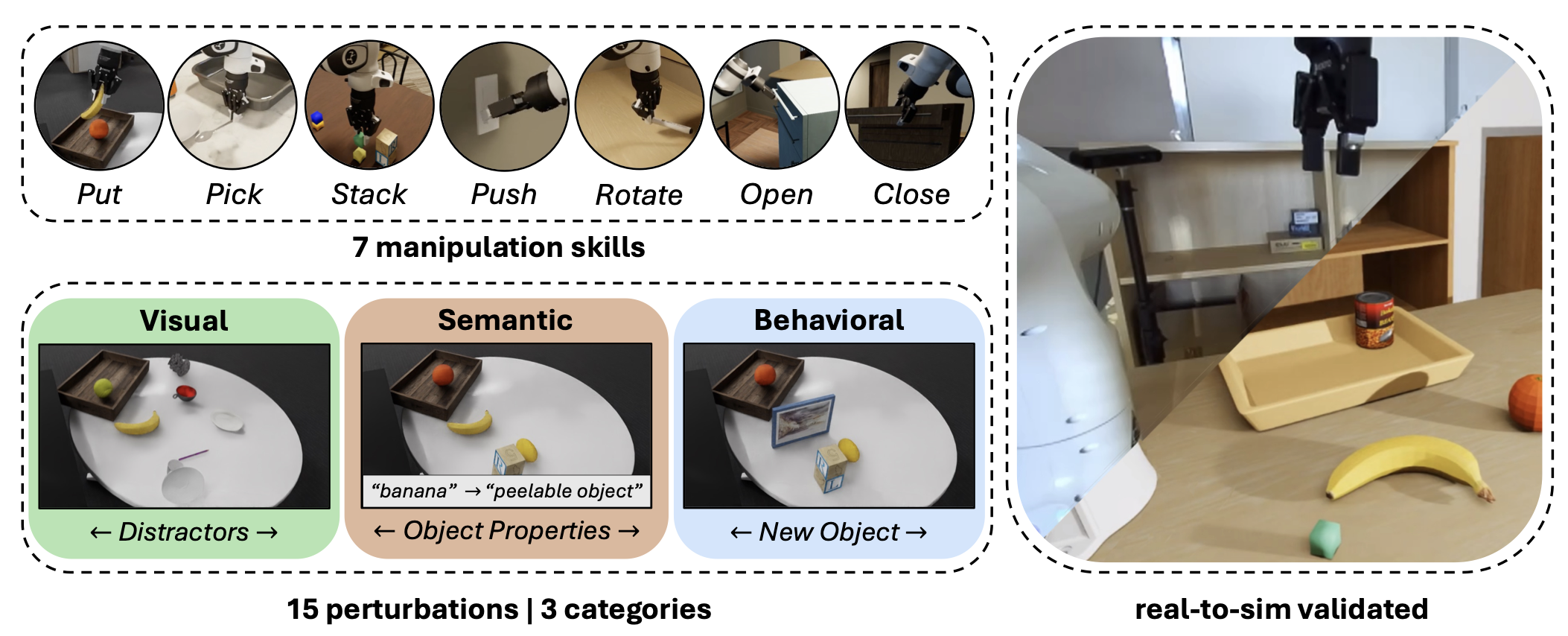 | Martin Sedlacek, Pavlo Yefanov, Georgy Ponimatkin, Jai Bardhan, Simon Pilc, Mederic Fourmy, Evangelos Kazakos, Cees G M Snoek, Josef Sivic, Vladimir Petrik: REALM: A Real-to-Sim Validated Benchmark for Generalization in Robotic Manipulation. In: IEEE Robotics and Automation Letters, vol. 11, iss. 7, pp. 8315-8322, 2026. @article{SedlacekRAL2026,
title = {REALM: A Real-to-Sim Validated Benchmark for Generalization in Robotic Manipulation},
author = {Martin Sedlacek and Pavlo Yefanov and Georgy Ponimatkin and Jai Bardhan and Simon Pilc and Mederic Fourmy and Evangelos Kazakos and Cees G M Snoek and Josef Sivic and Vladimir Petrik},
url = {https://arxiv.org/abs/2512.19562
https://martin-sedlacek.com/realm/
https://github.com/martin-sedlacek/REALM},
year = {2026},
date = {2026-04-12},
urldate = {2026-04-12},
journal = {IEEE Robotics and Automation Letters},
volume = {11},
issue = {7},
pages = {8315-8322},
abstract = {Vision-Language-Action (VLA) models empower robots to understand and execute tasks described by natural language instructions. However, a key challenge lies in their ability to generalize beyond the specific environments and conditions they were trained on, which is presently difficult and expensive to evaluate in the real-world. To address this gap, we present REALM, a new simulation environment and benchmark designed to evaluate the generalization capabilities of VLA models, with a specific emphasis on establishing a strong correlation between simulated and real-world performance through high-fidelity visuals and aligned robot control. Our environment offers a suite of 15 perturbation factors, 7 manipulation skills, and more than 3,500 objects. Finally, we establish two task sets that form our benchmark and evaluate the pi_{0}, pi_{0}-FAST, and GR00T N1.5 VLA models, showing that generalization and robustness remain an open challenge. More broadly, we also show that simulation gives us a valuable proxy for the real-world and allows us to systematically probe for and quantify the weaknesses and failure modes of VLAs.},
howpublished = {arXiv:2512.19562},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Vision-Language-Action (VLA) models empower robots to understand and execute tasks described by natural language instructions. However, a key challenge lies in their ability to generalize beyond the specific environments and conditions they were trained on, which is presently difficult and expensive to evaluate in the real-world. To address this gap, we present REALM, a new simulation environment and benchmark designed to evaluate the generalization capabilities of VLA models, with a specific emphasis on establishing a strong correlation between simulated and real-world performance through high-fidelity visuals and aligned robot control. Our environment offers a suite of 15 perturbation factors, 7 manipulation skills, and more than 3,500 objects. Finally, we establish two task sets that form our benchmark and evaluate the pi_{0}, pi_{0}-FAST, and GR00T N1.5 VLA models, showing that generalization and robustness remain an open challenge. More broadly, we also show that simulation gives us a valuable proxy for the real-world and allows us to systematically probe for and quantify the weaknesses and failure modes of VLAs. |
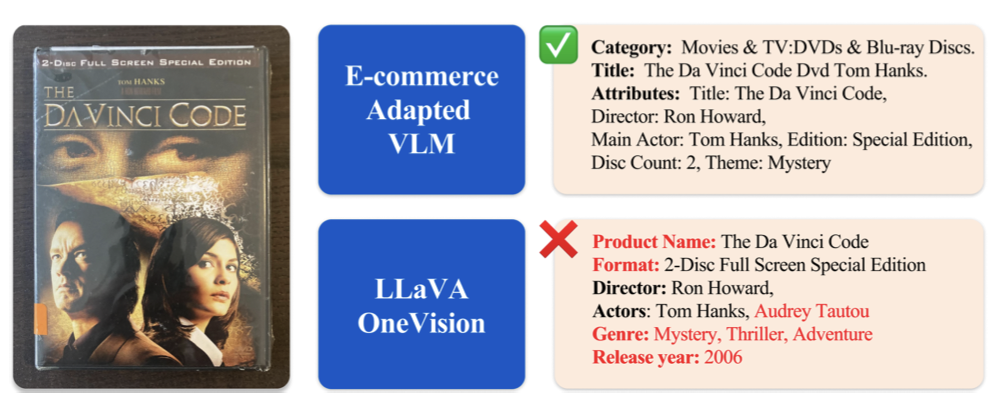 | Matteo Nulli, Orshulevich Vladimir, Tala Bazazo, Christian Herold, Michael Kozielski, Marcin Mazur, Szymon Tuzel, Cees G M Snoek, Seyyed Hadi Hashemi, Omar Javed, Yannick Versley, Shahram Khadivi: Adapting Vision-Language Models for E-Commerce Understanding at Scale. In: EACL, 2026. @inproceedings{NulliEACL2026,
title = {Adapting Vision-Language Models for E-Commerce Understanding at Scale},
author = {Matteo Nulli and Orshulevich Vladimir and Tala Bazazo and Christian Herold and Michael Kozielski and Marcin Mazur and Szymon Tuzel and Cees G M Snoek and Seyyed Hadi Hashemi and Omar Javed and Yannick Versley and Shahram Khadivi},
url = {https://matteonulli.github.io/assets/pdf/vlm_ebay_paper_adaptatio_deanon.pdf},
year = {2026},
date = {2026-03-24},
urldate = {2026-03-24},
booktitle = {EACL},
abstract = {E-commerce product understanding demands by nature, strong multimodal comprehension from text, images, and structured attributes. General-purpose Vision–Language Models (VLMs) enable generalizable multimodal latent modelling, yet there is no documented, well-known strategy for adapting them to the attribute-centric, multi-image, and noisy nature of e-commerce data, without sacrificing general performance. In this work, we show through a large-scale experimental study, how targeted adaptation of general VLMs can substantially improve e-commerce performance while preserving broad multimodal capabilities. Furthermore, we propose a novel extensive evaluation suite covering deep product understanding, strict instruction following, and dynamic attribute extraction.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
E-commerce product understanding demands by nature, strong multimodal comprehension from text, images, and structured attributes. General-purpose Vision–Language Models (VLMs) enable generalizable multimodal latent modelling, yet there is no documented, well-known strategy for adapting them to the attribute-centric, multi-image, and noisy nature of e-commerce data, without sacrificing general performance. In this work, we show through a large-scale experimental study, how targeted adaptation of general VLMs can substantially improve e-commerce performance while preserving broad multimodal capabilities. Furthermore, we propose a novel extensive evaluation suite covering deep product understanding, strict instruction following, and dynamic attribute extraction. |
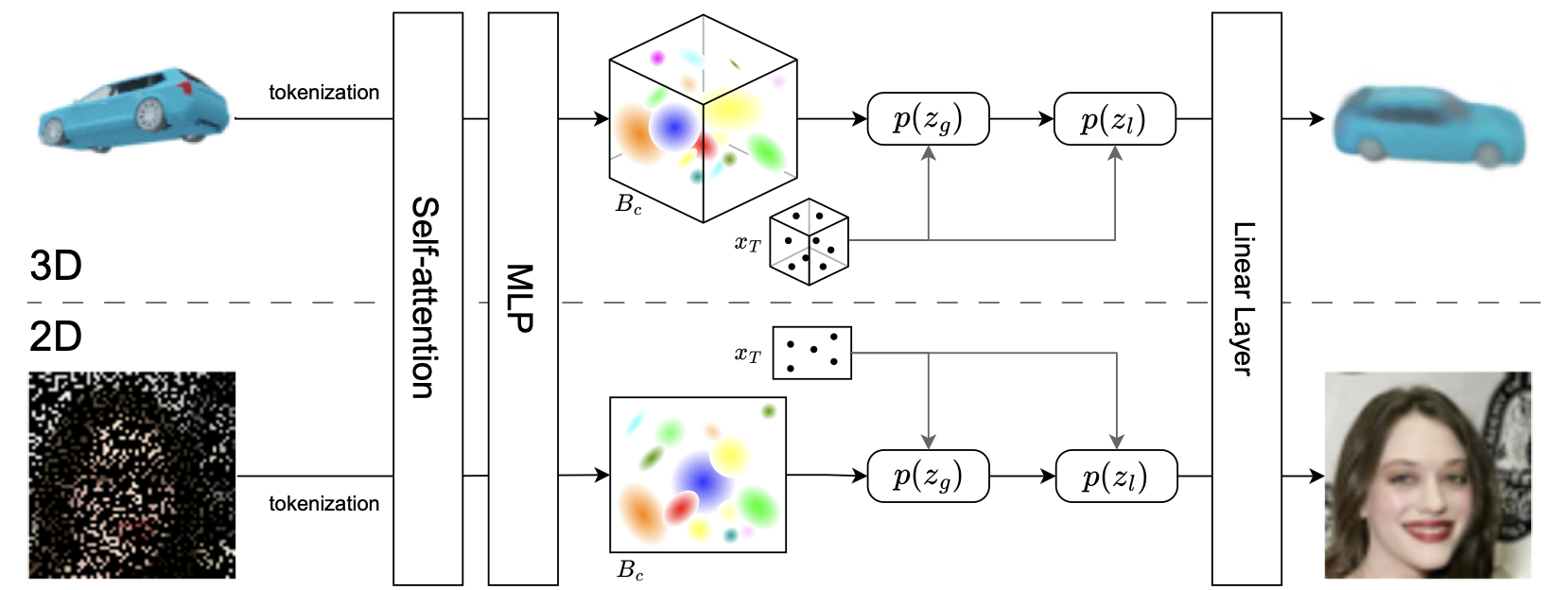 | Wenzhe Yin, Zehao Xiao, Jiayi Shen, Yunlu Chen, Cees G M Snoek, Jan-Jakob Sonke, Efstratios Gavves: Geometric Neural Process Fields. In: Transactions on Machine Learning Research, 2026. @article{YinTMLR2026,
title = {Geometric Neural Process Fields},
author = {Wenzhe Yin and Zehao Xiao and Jiayi Shen and Yunlu Chen and Cees G M Snoek and Jan-Jakob Sonke and Efstratios Gavves},
url = {https://arxiv.org/abs/2502.02338},
year = {2026},
date = {2026-03-23},
urldate = {2025-02-04},
journal = {Transactions on Machine Learning Research},
abstract = {This paper addresses the challenge of Neural Field (NeF) generalization, where models must efficiently adapt to new signals given only a few observations. To tackle this, we propose Geometric Neural Process Fields (G-NPF), a probabilistic framework for neural radiance fields that explicitly captures uncertainty. We formulate NeF generalization as a probabilistic problem, enabling direct inference of NeF function distributions from limited context observations. To incorporate structural inductive biases, we introduce a set of geometric bases that encode spatial structure and facilitate the inference of NeF function distributions. Building on these bases, we design a hierarchical latent variable model, allowing G-NPF to integrate structural information across multiple spatial levels and effectively parameterize INR functions. This hierarchical approach improves generalization to novel scenes and unseen signals. Experiments on novel-view synthesis for 3D scenes, as well as 2D image and 1D signal regression, demonstrate the effectiveness of our method in capturing uncertainty and leveraging structural information for improved generalization.},
howpublished = {arXiv:2502.02338},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
This paper addresses the challenge of Neural Field (NeF) generalization, where models must efficiently adapt to new signals given only a few observations. To tackle this, we propose Geometric Neural Process Fields (G-NPF), a probabilistic framework for neural radiance fields that explicitly captures uncertainty. We formulate NeF generalization as a probabilistic problem, enabling direct inference of NeF function distributions from limited context observations. To incorporate structural inductive biases, we introduce a set of geometric bases that encode spatial structure and facilitate the inference of NeF function distributions. Building on these bases, we design a hierarchical latent variable model, allowing G-NPF to integrate structural information across multiple spatial levels and effectively parameterize INR functions. This hierarchical approach improves generalization to novel scenes and unseen signals. Experiments on novel-view synthesis for 3D scenes, as well as 2D image and 1D signal regression, demonstrate the effectiveness of our method in capturing uncertainty and leveraging structural information for improved generalization. |
 | Wenfang Sun, Yingjun Du, Gaowen Liu, Cees G M Snoek: QUOTA: Quantifying Objects with Text-to-Image Models for Any Domain. In: WACV, 2026. @inproceedings{SunWACV2026,
title = {QUOTA: Quantifying Objects with Text-to-Image Models for Any Domain},
author = {Wenfang Sun and Yingjun Du and Gaowen Liu and Cees G M Snoek},
url = {https://arxiv.org/abs/2411.19534},
year = {2026},
date = {2026-03-06},
urldate = {2024-11-29},
booktitle = {WACV},
abstract = {We tackle the problem of quantifying the number of objects by a generative text-to-image model. Rather than retraining such a model for each new image domain of interest, which leads to high computational costs and limited scalability, we are the first to consider this problem from a domain-agnostic perspective. We propose QUOTA, an optimization framework for text-to-image models that enables effective object quantification across unseen domains without retraining. It leverages a dual-loop meta-learning strategy to optimize a domain-invariant prompt. Further, by integrating prompt learning with learnable counting and domain tokens, our method captures stylistic variations and maintains accuracy, even for object classes not encountered during training. For evaluation, we adopt a new benchmark specifically designed for object quantification in domain generalization, enabling rigorous assessment of object quantification accuracy and adaptability across unseen domains in text-to-image generation. Extensive experiments demonstrate that QUOTA outperforms conventional models in both object quantification accuracy and semantic consistency, setting a new benchmark for efficient and scalable text-to-image generation for any domain.},
howpublished = {arXiv:2411.19534},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
We tackle the problem of quantifying the number of objects by a generative text-to-image model. Rather than retraining such a model for each new image domain of interest, which leads to high computational costs and limited scalability, we are the first to consider this problem from a domain-agnostic perspective. We propose QUOTA, an optimization framework for text-to-image models that enables effective object quantification across unseen domains without retraining. It leverages a dual-loop meta-learning strategy to optimize a domain-invariant prompt. Further, by integrating prompt learning with learnable counting and domain tokens, our method captures stylistic variations and maintains accuracy, even for object classes not encountered during training. For evaluation, we adopt a new benchmark specifically designed for object quantification in domain generalization, enabling rigorous assessment of object quantification accuracy and adaptability across unseen domains in text-to-image generation. Extensive experiments demonstrate that QUOTA outperforms conventional models in both object quantification accuracy and semantic consistency, setting a new benchmark for efficient and scalable text-to-image generation for any domain. |
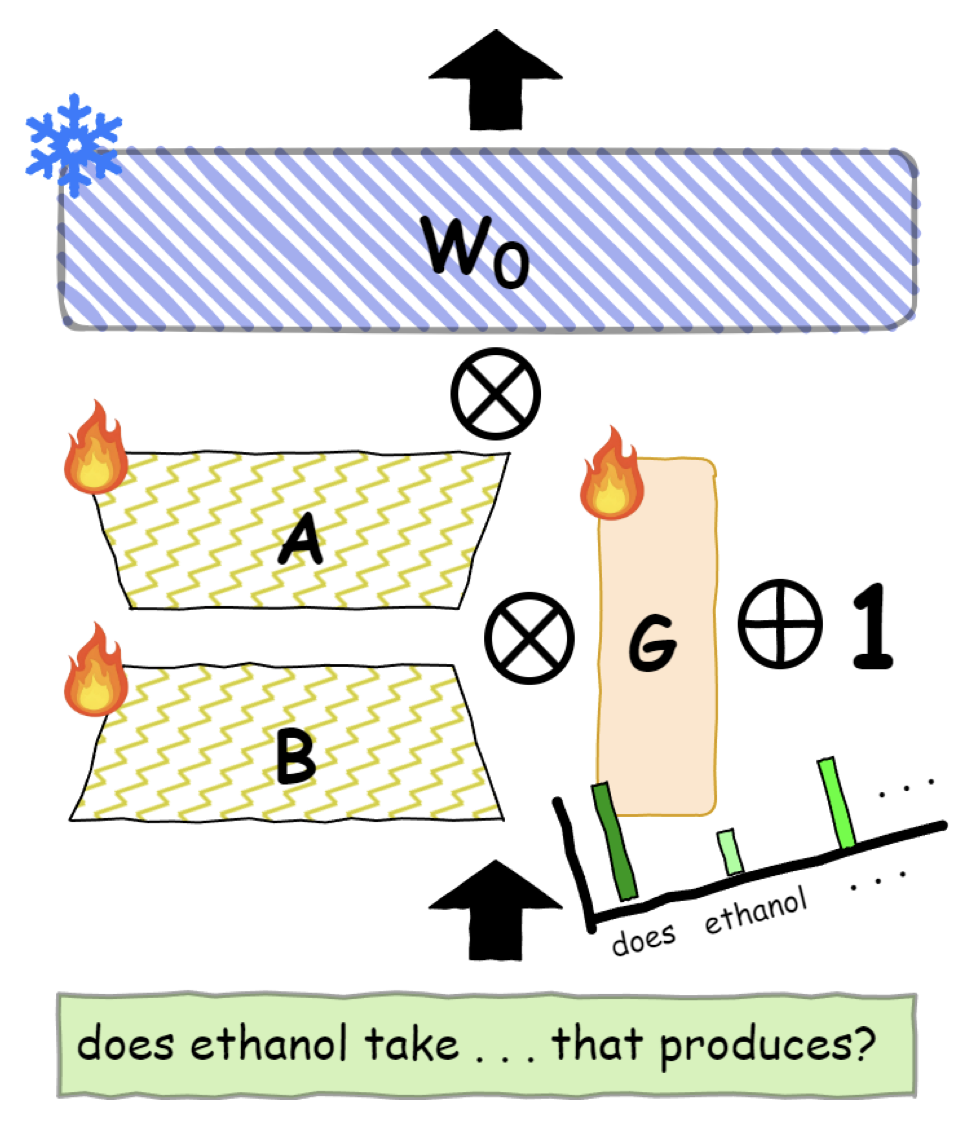 | Jie Ou, Shuaihong Jiang, Yingjun Du, Cees G M Snoek: GateRA: Token-Aware Modulation for Parameter-Efficient Fine-Tuning. In: AAAI, 2026. @inproceedings{OuAAAI2026,
title = {GateRA: Token-Aware Modulation for Parameter-Efficient Fine-Tuning},
author = {Jie Ou and Shuaihong Jiang and Yingjun Du and Cees G M Snoek},
url = {https://arxiv.org/abs/2511.17582},
year = {2026},
date = {2026-01-20},
urldate = {2026-01-20},
booktitle = {AAAI},
abstract = {Parameter-efficient fine-tuning (PEFT) methods, such as LoRA, DoRA, and HiRA, enable lightweight adaptation of large pre-trained models via low-rank updates. However, existing PEFT approaches apply static, input-agnostic updates to all tokens, disregarding the varying importance and difficulty of different inputs. This uniform treatment can lead to overfitting on trivial content or under-adaptation on more informative regions, especially in autoregressive settings with distinct prefill and decoding dynamics. In this paper, we propose GateRA, a unified framework that introduces token-aware modulation to dynamically adjust the strength of PEFT updates. By incorporating adaptive gating into standard PEFT branches, GateRA enables selective, token-level adaptation, preserving pre-trained knowledge for well-modeled inputs while focusing capacity on challenging cases. Empirical visualizations reveal phase-sensitive behaviors, where GateRA automatically suppresses updates for redundant prefill tokens while emphasizing adaptation during decoding. To promote confident and efficient modulation, we further introduce an entropy-based regularization that encourages near-binary gating decisions. This regularization prevents diffuse update patterns and leads to interpretable, sparse adaptation without hard thresholding. Finally, we present a theoretical analysis showing that GateRA induces a soft gradient-masking effect over the PEFT path, enabling continuous and differentiable control over adaptation. Experiments on multiple commonsense reasoning benchmarks demonstrate that GateRA consistently outperforms or matches prior PEFT methods.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Parameter-efficient fine-tuning (PEFT) methods, such as LoRA, DoRA, and HiRA, enable lightweight adaptation of large pre-trained models via low-rank updates. However, existing PEFT approaches apply static, input-agnostic updates to all tokens, disregarding the varying importance and difficulty of different inputs. This uniform treatment can lead to overfitting on trivial content or under-adaptation on more informative regions, especially in autoregressive settings with distinct prefill and decoding dynamics. In this paper, we propose GateRA, a unified framework that introduces token-aware modulation to dynamically adjust the strength of PEFT updates. By incorporating adaptive gating into standard PEFT branches, GateRA enables selective, token-level adaptation, preserving pre-trained knowledge for well-modeled inputs while focusing capacity on challenging cases. Empirical visualizations reveal phase-sensitive behaviors, where GateRA automatically suppresses updates for redundant prefill tokens while emphasizing adaptation during decoding. To promote confident and efficient modulation, we further introduce an entropy-based regularization that encourages near-binary gating decisions. This regularization prevents diffuse update patterns and leads to interpretable, sparse adaptation without hard thresholding. Finally, we present a theoretical analysis showing that GateRA induces a soft gradient-masking effect over the PEFT path, enabling continuous and differentiable control over adaptation. Experiments on multiple commonsense reasoning benchmarks demonstrate that GateRA consistently outperforms or matches prior PEFT methods. |
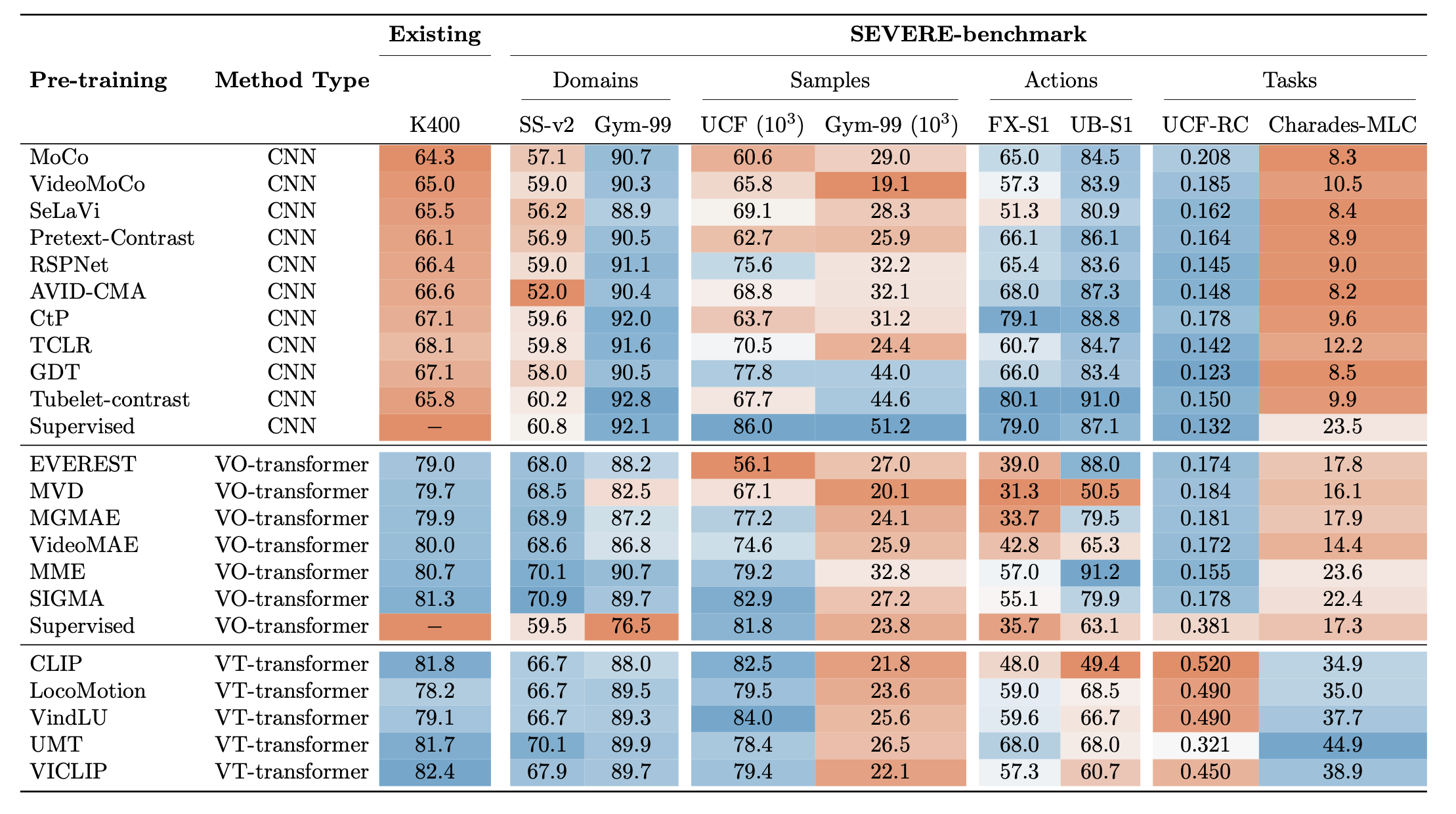 | Fida Mohammad Thoker, Letian Jiang, Chen Zhao, Piyush Bagad, Hazel Doughty, Bernard Ghanem, Cees G M Snoek: SEVERE++: Evaluating Benchmark Sensitivity in Generalization of Video Representation Learning. In: International Journal of Computer Vision, 2026, (Submitted.). @article{ThokerIJCV2025,
title = {SEVERE++: Evaluating Benchmark Sensitivity in Generalization of Video Representation Learning},
author = {Fida Mohammad Thoker and Letian Jiang and Chen Zhao and Piyush Bagad and Hazel Doughty and Bernard Ghanem and Cees G M Snoek},
url = {https://arxiv.org/abs/2504.05706},
year = {2026},
date = {2026-01-01},
urldate = {2025-04-08},
journal = {International Journal of Computer Vision},
abstract = {Continued advances in self-supervised learning have led to significant progress in video representation learning, offering a scalable alternative to supervised approaches by removing the need for manual annotations. Despite strong performance on standard action recognition benchmarks, video self-supervised learning methods are largely evaluated under narrow protocols, typically pretraining on Kinetics-400 and fine-tuning on similar datasets, limiting our understanding of their generalization in real world scenarios. In this work, we present a comprehensive evaluation of modern video self-supervised models, focusing on generalization across four key downstream factors: domain shift, sample efficiency, action granularity, and task diversity. Building on our prior work analyzing benchmark sensitivity in CNN-based contrastive learning, we extend the study to cover state-of-the-art transformer-based video-only and video-text models. Specifically, we benchmark 12 transformer-based methods (7 video-only, 5 video-text) and compare them to 10 CNN-based methods, totaling over 1100 experiments across 8 datasets and 7 downstream tasks. Our analysis shows that, despite architectural advances, transformer-based models remain sensitive to downstream conditions. No method generalizes consistently across all factors, video-only transformers perform better under domain shifts, CNNs outperform for fine-grained tasks, and video-text models often underperform despite large scale pretraining. We also find that recent transformer models do not consistently outperform earlier approaches. Our findings provide a detailed view of the strengths and limitations of current video SSL methods and offer a unified benchmark for evaluating generalization in video representation learning.},
note = {Submitted.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Continued advances in self-supervised learning have led to significant progress in video representation learning, offering a scalable alternative to supervised approaches by removing the need for manual annotations. Despite strong performance on standard action recognition benchmarks, video self-supervised learning methods are largely evaluated under narrow protocols, typically pretraining on Kinetics-400 and fine-tuning on similar datasets, limiting our understanding of their generalization in real world scenarios. In this work, we present a comprehensive evaluation of modern video self-supervised models, focusing on generalization across four key downstream factors: domain shift, sample efficiency, action granularity, and task diversity. Building on our prior work analyzing benchmark sensitivity in CNN-based contrastive learning, we extend the study to cover state-of-the-art transformer-based video-only and video-text models. Specifically, we benchmark 12 transformer-based methods (7 video-only, 5 video-text) and compare them to 10 CNN-based methods, totaling over 1100 experiments across 8 datasets and 7 downstream tasks. Our analysis shows that, despite architectural advances, transformer-based models remain sensitive to downstream conditions. No method generalizes consistently across all factors, video-only transformers perform better under domain shifts, CNNs outperform for fine-grained tasks, and video-text models often underperform despite large scale pretraining. We also find that recent transformer models do not consistently outperform earlier approaches. Our findings provide a detailed view of the strengths and limitations of current video SSL methods and offer a unified benchmark for evaluating generalization in video representation learning. |
 | Piyush Bagad, Makarand Tapaswi, Cees G M Snoek, Andrew Zisserman: The Sound of Water: Inferring Physical Properties from Pouring Liquids. In: IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026, (In press). @article{BagadTPAMI2026,
title = {The Sound of Water: Inferring Physical Properties from Pouring Liquids},
author = {Piyush Bagad and Makarand Tapaswi and Cees G M Snoek and Andrew Zisserman},
url = {https://arxiv.org/abs/2411.11222},
year = {2026},
date = {2026-01-01},
urldate = {2026-01-01},
journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence},
abstract = {We study the connection between audio observations and the underlying physics of a mundane yet intriguing everyday activity: pouring liquids. Given only the sound of liquid pouring into a container, our objective is to automatically infer physical properties such as the liquid level, the shape and size of the container, the pouring rate and the time to fill. To this end, we: (i) show in theory that these properties can be determined from the fundamental frequency (pitch); (ii) train a pitch detection model with supervision from simulated data and visual data with a physics-inspired objective; (iii) introduce a new large dataset of real pouring videos for a systematic study; (iv) show that the trained model can indeed infer these physical properties for real data; and finally, (v) we demonstrate strong generalization to various container shapes, other datasets, and in-the-wild YouTube videos. Our work presents a keen understanding of a narrow yet rich problem at the intersection of acoustics, physics, and learning. It opens up applications to enhance multisensory perception in robotic pouring.},
note = {In press},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
We study the connection between audio observations and the underlying physics of a mundane yet intriguing everyday activity: pouring liquids. Given only the sound of liquid pouring into a container, our objective is to automatically infer physical properties such as the liquid level, the shape and size of the container, the pouring rate and the time to fill. To this end, we: (i) show in theory that these properties can be determined from the fundamental frequency (pitch); (ii) train a pitch detection model with supervision from simulated data and visual data with a physics-inspired objective; (iii) introduce a new large dataset of real pouring videos for a systematic study; (iv) show that the trained model can indeed infer these physical properties for real data; and finally, (v) we demonstrate strong generalization to various container shapes, other datasets, and in-the-wild YouTube videos. Our work presents a keen understanding of a narrow yet rich problem at the intersection of acoustics, physics, and learning. It opens up applications to enhance multisensory perception in robotic pouring. |
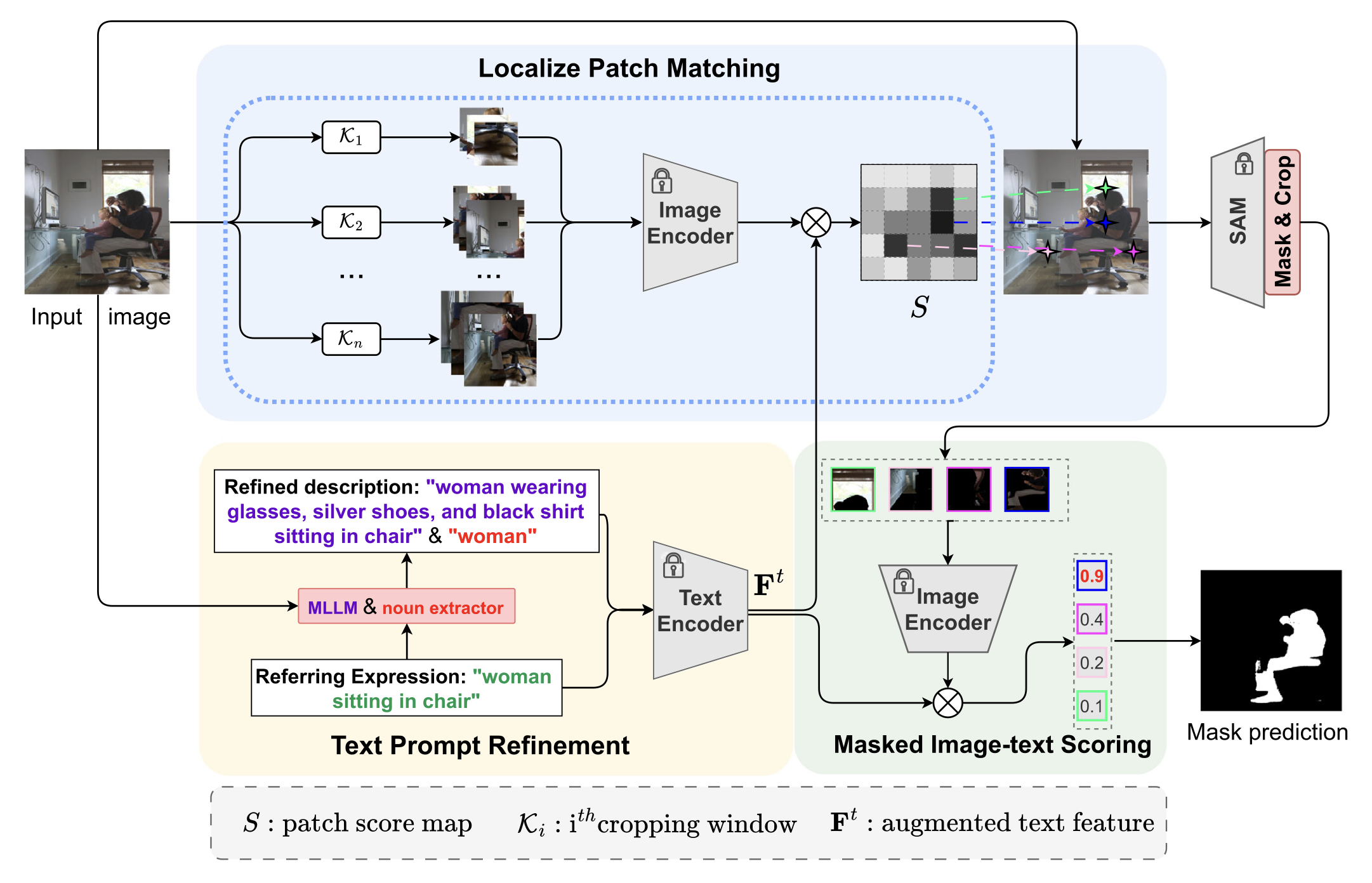 | Lei Zhang, Yongqiu Huang, Yingjun Du, Fang Lei, Zhiying Yang, Cees G M Snoek, Yehui Wang: LoTeR: Localized text prompt refinement for zero-shot referring image segmentation. In: Computer Vision and Image Understanding, vol. 263, iss. January, no. 104596, 2026. @article{ZhangCVIU2026,
title = {LoTeR: Localized text prompt refinement for zero-shot referring image segmentation},
author = {Lei Zhang and Yongqiu Huang and Yingjun Du, Fang Lei and Zhiying Yang and Cees G M Snoek and Yehui Wang},
url = {https://www.sciencedirect.com/science/article/pii/S1077314225003194},
doi = {https://doi.org/10.1016/j.cviu.2025.104596},
year = {2026},
date = {2026-01-01},
journal = {Computer Vision and Image Understanding},
volume = {263},
number = {104596},
issue = {January},
abstract = {This paper addresses the challenge of segmenting an object in an image based solely on a textual description, without requiring any training on specific object classes. In contrast to traditional methods that rely on generating numerous mask proposals, we introduce a novel patch-based approach. Our method computes the similarity between small image patches, extracted using a sliding window, and textual descriptions, producing a patch score map that identifies the regions most likely to contain the target object. This score map guides a segment-anything model to generate precise mask proposals. To further improve segmentation accuracy, we refine the textual prompts by generating detailed object descriptions using a multi-modal large language model. Our method’s effectiveness is validated through extensive experiments on the RefCOCO, RefCOCO+, and RefCOCOg datasets, where it outperforms state-of-the-art zero-shot referring image segmentation methods. Ablation studies confirm the key contributions of our patch-based segmentation and localized text prompt refinement, demonstrating their significant role in enhancing both precision and robustness.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
This paper addresses the challenge of segmenting an object in an image based solely on a textual description, without requiring any training on specific object classes. In contrast to traditional methods that rely on generating numerous mask proposals, we introduce a novel patch-based approach. Our method computes the similarity between small image patches, extracted using a sliding window, and textual descriptions, producing a patch score map that identifies the regions most likely to contain the target object. This score map guides a segment-anything model to generate precise mask proposals. To further improve segmentation accuracy, we refine the textual prompts by generating detailed object descriptions using a multi-modal large language model. Our method’s effectiveness is validated through extensive experiments on the RefCOCO, RefCOCO+, and RefCOCOg datasets, where it outperforms state-of-the-art zero-shot referring image segmentation methods. Ablation studies confirm the key contributions of our patch-based segmentation and localized text prompt refinement, demonstrating their significant role in enhancing both precision and robustness. |
2025
|
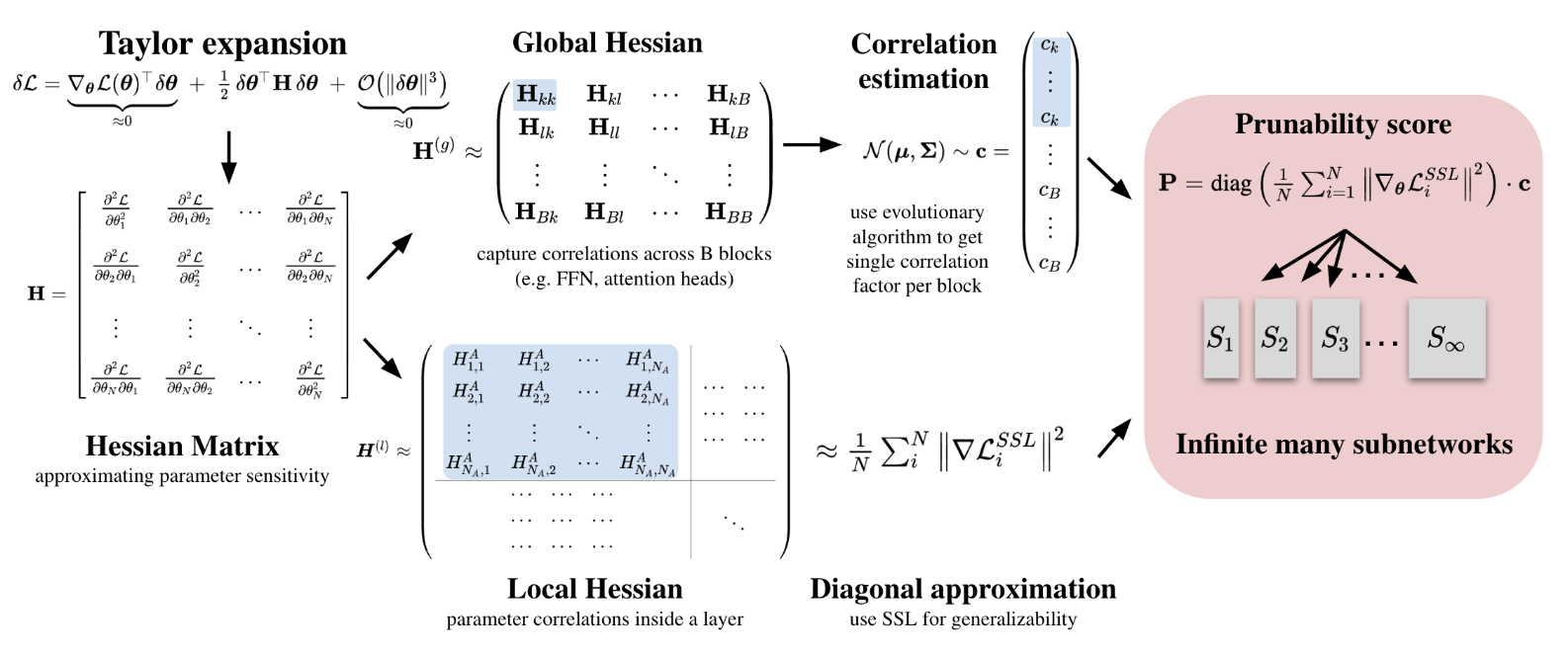 | Walter Simoncini, Michael Dorkenwald, Tijmen Blankevoort, Cees G M Snoek, Yuki M Asano: Elastic ViTs from Pretrained Models without Retraining. In: NeurIPS, 2025. @inproceedings{SimonciniNeurips25,
title = {Elastic ViTs from Pretrained Models without Retraining},
author = {Walter Simoncini and Michael Dorkenwald and Tijmen Blankevoort and Cees G M Snoek and Yuki M Asano},
url = {https://arxiv.org/abs/2510.17700
https://elastic.ashita.nl},
year = {2025},
date = {2025-12-02},
urldate = {2025-12-02},
booktitle = {NeurIPS},
abstract = {Vision foundation models achieve remarkable performance but are only available in a limited set of pre-determined sizes, forcing sub-optimal deployment choices under real-world constraints. We introduce SnapViT: Single-shot network approximation for pruned Vision Transformers, a new post-pretraining structured pruning method that enables elastic inference across a continuum of compute budgets. Our approach efficiently combines gradient information with cross-network structure correlations, approximated via an evolutionary algorithm, does not require labeled data, generalizes to models without a classification head, and is retraining-free. Experiments on DINO, SigLIPv2, DeIT, and AugReg models demonstrate superior performance over state-of-the-art methods across various sparsities, requiring less than five minutes on a single A100 GPU to generate elastic models that can be adjusted to any computational budget. Our key contributions include an efficient pruning strategy for pretrained Vision Transformers, a novel evolutionary approximation of Hessian off-diagonal structures, and a self-supervised importance scoring mechanism that maintains strong performance without requiring retraining or labels.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Vision foundation models achieve remarkable performance but are only available in a limited set of pre-determined sizes, forcing sub-optimal deployment choices under real-world constraints. We introduce SnapViT: Single-shot network approximation for pruned Vision Transformers, a new post-pretraining structured pruning method that enables elastic inference across a continuum of compute budgets. Our approach efficiently combines gradient information with cross-network structure correlations, approximated via an evolutionary algorithm, does not require labeled data, generalizes to models without a classification head, and is retraining-free. Experiments on DINO, SigLIPv2, DeIT, and AugReg models demonstrate superior performance over state-of-the-art methods across various sparsities, requiring less than five minutes on a single A100 GPU to generate elastic models that can be adjusted to any computational budget. Our key contributions include an efficient pruning strategy for pretrained Vision Transformers, a novel evolutionary approximation of Hessian off-diagonal structures, and a self-supervised importance scoring mechanism that maintains strong performance without requiring retraining or labels. |
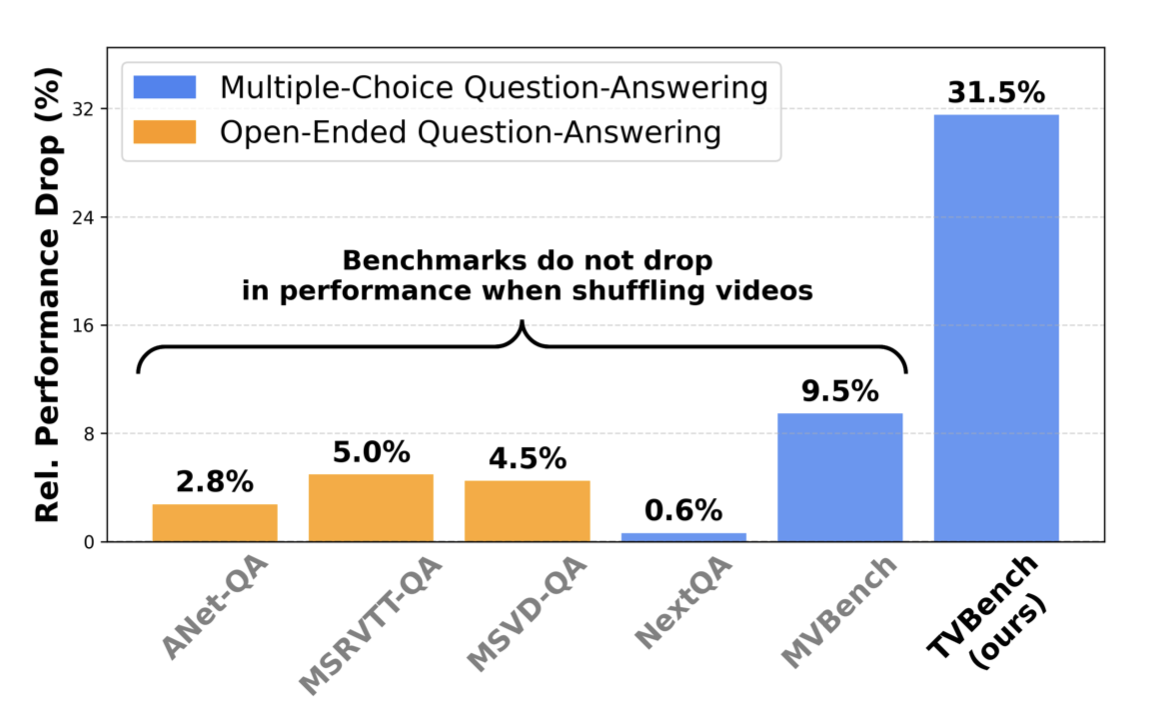 | Daniel Cores, Michael Dorkenwald, Manuel Mucientes, Cees G M Snoek, Yuki M Asano: Lost in Time: A New Temporal Benchmark for VideoLLMs. In: BMVC, 2025. @inproceedings{CoresBMVC2025,
title = {Lost in Time: A New Temporal Benchmark for VideoLLMs},
author = {Daniel Cores and Michael Dorkenwald and Manuel Mucientes and Cees G M Snoek and Yuki M Asano},
url = {https://arxiv.org/abs/2410.07752},
year = {2025},
date = {2025-11-24},
urldate = {2025-11-24},
booktitle = {BMVC},
abstract = {Large language models have demonstrated impressive performance when integrated with vision models even enabling video understanding. However, evaluating video models presents its own unique challenges, for which several benchmarks have been proposed. In this paper, we show that the currently most used video-language benchmarks can be solved without requiring much temporal reasoning. We identified three main issues in existing datasets: (i) static information from single frames is often sufficient to solve the tasks (ii) the text of the questions and candidate answers is overly informative, allowing models to answer correctly without relying on any visual input (iii) world knowledge alone can answer many of the questions, making the benchmarks a test of knowledge replication rather than video reasoning. In addition, we found that open-ended question-answering benchmarks for video understanding suffer from similar issues while the automatic evaluation process with LLMs is unreliable, making it an unsuitable alternative. As a solution, we propose TVBench, a novel open-source video multiple-choice question-answering benchmark, and demonstrate through extensive evaluations that it requires a high level of temporal understanding. Surprisingly, we find that many recent video-language models perform similarly to random performance on TVBench, with only a few models such as Aria, Qwen2-VL, and Tarsier surpassing this baseline.},
howpublished = {arXiv:2410.07752},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Large language models have demonstrated impressive performance when integrated with vision models even enabling video understanding. However, evaluating video models presents its own unique challenges, for which several benchmarks have been proposed. In this paper, we show that the currently most used video-language benchmarks can be solved without requiring much temporal reasoning. We identified three main issues in existing datasets: (i) static information from single frames is often sufficient to solve the tasks (ii) the text of the questions and candidate answers is overly informative, allowing models to answer correctly without relying on any visual input (iii) world knowledge alone can answer many of the questions, making the benchmarks a test of knowledge replication rather than video reasoning. In addition, we found that open-ended question-answering benchmarks for video understanding suffer from similar issues while the automatic evaluation process with LLMs is unreliable, making it an unsuitable alternative. As a solution, we propose TVBench, a novel open-source video multiple-choice question-answering benchmark, and demonstrate through extensive evaluations that it requires a high level of temporal understanding. Surprisingly, we find that many recent video-language models perform similarly to random performance on TVBench, with only a few models such as Aria, Qwen2-VL, and Tarsier surpassing this baseline. |
 | Aritra Bhowmik, Mohammad Mahdi Derakhshani, Dennis Koelma, Yuki M Asano, Martin R Oswald, Cees G M Snoek: TWIST & SCOUT: Grounding Multimodal LLM-Experts by Forget-Free Tuning. In: ICCV, 2025. @inproceedings{BhowmikICCV2025,
title = {TWIST & SCOUT: Grounding Multimodal LLM-Experts by Forget-Free Tuning},
author = {Aritra Bhowmik and Mohammad Mahdi Derakhshani and Dennis Koelma and Yuki M Asano and Martin R Oswald and Cees G M Snoek},
url = {https://arxiv.org/abs/2410.10491},
year = {2025},
date = {2025-10-19},
urldate = {2025-03-20},
booktitle = {ICCV},
abstract = {Spatial awareness is key to enable embodied multimodal AI systems. Yet, without vast amounts of spatial supervision, current Multimodal Large Language Models (MLLMs) struggle at this task. In this paper, we introduce TWIST & SCOUT, a framework that equips pre-trained MLLMs with visual grounding ability without forgetting their existing image and language understanding skills. To this end, we propose TWIST, a twin-expert stepwise tuning module that modifies the decoder of the language model using one frozen module pre-trained on image understanding tasks and another learnable one for visual grounding tasks. This allows the MLLM to retain previously learned knowledge and skills, while acquiring what is missing. To fine-tune the model effectively, we generate a high-quality synthetic dataset we call SCOUT, which mimics human reasoning in visual grounding. This dataset provides rich supervision signals, describing a step-by-step multimodal reasoning process, thereby simplifying the task of visual grounding. We evaluate our approach on several standard benchmark datasets, encompassing grounded image captioning, zero-shot localization, and visual grounding tasks. Our method consistently delivers strong performance across all tasks, while retaining the pre-trained image understanding capabilities.},
howpublished = {arXiv:2410.10491},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Spatial awareness is key to enable embodied multimodal AI systems. Yet, without vast amounts of spatial supervision, current Multimodal Large Language Models (MLLMs) struggle at this task. In this paper, we introduce TWIST & SCOUT, a framework that equips pre-trained MLLMs with visual grounding ability without forgetting their existing image and language understanding skills. To this end, we propose TWIST, a twin-expert stepwise tuning module that modifies the decoder of the language model using one frozen module pre-trained on image understanding tasks and another learnable one for visual grounding tasks. This allows the MLLM to retain previously learned knowledge and skills, while acquiring what is missing. To fine-tune the model effectively, we generate a high-quality synthetic dataset we call SCOUT, which mimics human reasoning in visual grounding. This dataset provides rich supervision signals, describing a step-by-step multimodal reasoning process, thereby simplifying the task of visual grounding. We evaluate our approach on several standard benchmark datasets, encompassing grounded image captioning, zero-shot localization, and visual grounding tasks. Our method consistently delivers strong performance across all tasks, while retaining the pre-trained image understanding capabilities. |
 | Mohammadreza Salehi, Shashanka Venkataramanan, Ioana Simion, Efstratios Gavves, Cees G M Snoek, Yuki M Asano: MoSiC: Optimal-Transport Motion Trajectory for Dense Self-Supervised Learning. In: ICCV, 2025. @inproceedings{SalehiICCV2025,
title = {MoSiC: Optimal-Transport Motion Trajectory for Dense Self-Supervised Learning},
author = {Mohammadreza Salehi and Shashanka Venkataramanan and Ioana Simion and Efstratios Gavves and Cees G M Snoek and Yuki M Asano},
url = {https://arxiv.org/abs/2506.08694
https://github.com/SMSD75/MoSiC/tree/main},
year = {2025},
date = {2025-10-19},
urldate = {2025-10-19},
booktitle = {ICCV},
abstract = {Dense self-supervised learning has shown great promise for learning pixel- and patch-level representations, but extending it to videos remains challenging due to the complexity of motion dynamics. Existing approaches struggle as they rely on static augmentations that fail under object deformations, occlusions, and camera movement, leading to inconsistent feature learning over time. We propose a motion-guided self-supervised learning framework that clusters dense point tracks to learn spatiotemporally consistent representations. By leveraging an off-the-shelf point tracker, we extract long-range motion trajectories and optimize feature clustering through a momentum-encoder-based optimal transport mechanism. To ensure temporal coherence, we propagate cluster assignments along tracked points, enforcing feature consistency across views despite viewpoint changes. Integrating motion as an implicit supervisory signal, our method learns representations that generalize across frames, improving robustness in dynamic scenes and challenging occlusion scenarios. By initializing from strong image-pretrained models and leveraging video data for training, we improve state-of-the-art by 1% to 6% on six image and video datasets and four evaluation benchmarks.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Dense self-supervised learning has shown great promise for learning pixel- and patch-level representations, but extending it to videos remains challenging due to the complexity of motion dynamics. Existing approaches struggle as they rely on static augmentations that fail under object deformations, occlusions, and camera movement, leading to inconsistent feature learning over time. We propose a motion-guided self-supervised learning framework that clusters dense point tracks to learn spatiotemporally consistent representations. By leveraging an off-the-shelf point tracker, we extract long-range motion trajectories and optimize feature clustering through a momentum-encoder-based optimal transport mechanism. To ensure temporal coherence, we propagate cluster assignments along tracked points, enforcing feature consistency across views despite viewpoint changes. Integrating motion as an implicit supervisory signal, our method learns representations that generalize across frames, improving robustness in dynamic scenes and challenging occlusion scenarios. By initializing from strong image-pretrained models and leveraging video data for training, we improve state-of-the-art by 1% to 6% on six image and video datasets and four evaluation benchmarks. |
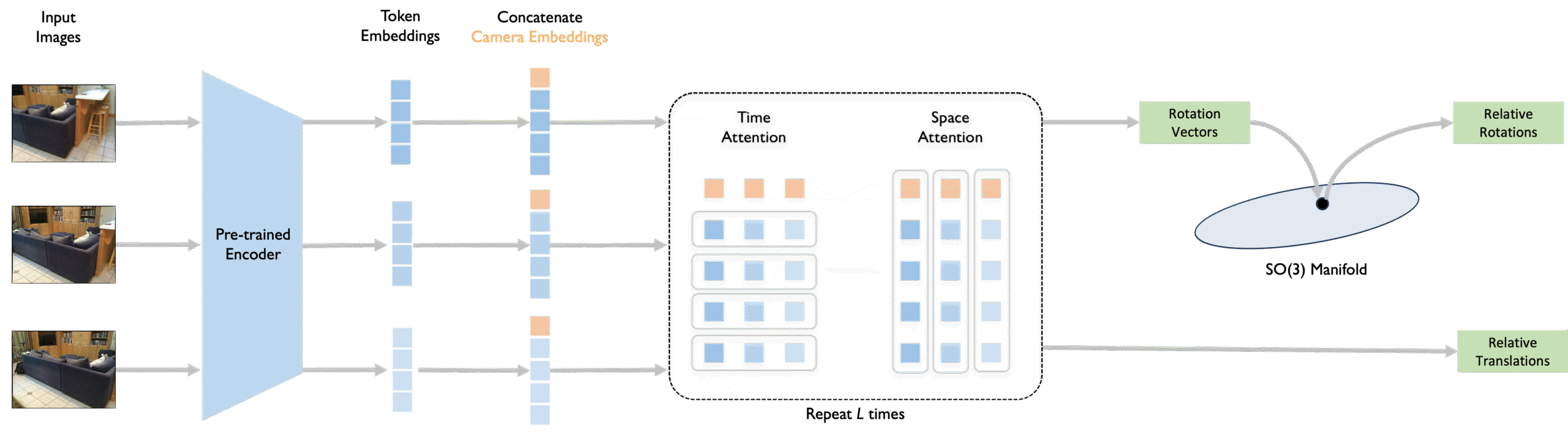 | Vladimir Yugay, Duy-Kien Nguyen, Theo Gevers, Cees G M Snoek, Martin R Oswald: Visual Odometry with Transformers. arXiv:2510.03348, 2025. @unpublished{YugayArxiv2025,
title = {Visual Odometry with Transformers},
author = {Vladimir Yugay and Duy-Kien Nguyen and Theo Gevers and Cees G M Snoek and Martin R Oswald},
url = {https://arxiv.org/abs/2510.03348
https://vladimiryugay.github.io/vot/},
year = {2025},
date = {2025-10-02},
abstract = {Modern monocular visual odometry methods typically combine pre-trained deep learning components with optimization modules, resulting in complex pipelines that rely heavily on camera calibration and hyperparameter tuning, and often struggle in unseen real-world scenarios. Recent large-scale 3D models trained on massive amounts of multi-modal data have partially alleviated these challenges, providing generalizable dense reconstruction and camera pose estimation. Still, they remain limited in handling long videos and providing accurate per-frame estimates, which are required for visual odometry. In this work, we demonstrate that monocular visual odometry can be addressed effectively in an end-to-end manner, thereby eliminating the need for handcrafted components such as bundle adjustment, feature matching, camera calibration, or dense 3D reconstruction. We introduce VoT, short for Visual odometry Transformer, which processes sequences of monocular frames by extracting features and modeling global relationships through temporal and spatial attention. Unlike prior methods, VoT directly predicts camera motion without estimating dense geometry and relies solely on camera poses for supervision. The framework is modular and flexible, allowing seamless integration of various pre-trained encoders as feature extractors. Experimental results demonstrate that VoT scales effectively with larger datasets, benefits substantially from stronger pre-trained backbones, generalizes across diverse camera motions and calibration settings, and outperforms traditional methods while running more than 3 times faster. },
howpublished = {arXiv:2510.03348},
keywords = {},
pubstate = {published},
tppubtype = {unpublished}
}
Modern monocular visual odometry methods typically combine pre-trained deep learning components with optimization modules, resulting in complex pipelines that rely heavily on camera calibration and hyperparameter tuning, and often struggle in unseen real-world scenarios. Recent large-scale 3D models trained on massive amounts of multi-modal data have partially alleviated these challenges, providing generalizable dense reconstruction and camera pose estimation. Still, they remain limited in handling long videos and providing accurate per-frame estimates, which are required for visual odometry. In this work, we demonstrate that monocular visual odometry can be addressed effectively in an end-to-end manner, thereby eliminating the need for handcrafted components such as bundle adjustment, feature matching, camera calibration, or dense 3D reconstruction. We introduce VoT, short for Visual odometry Transformer, which processes sequences of monocular frames by extracting features and modeling global relationships through temporal and spatial attention. Unlike prior methods, VoT directly predicts camera motion without estimating dense geometry and relies solely on camera poses for supervision. The framework is modular and flexible, allowing seamless integration of various pre-trained encoders as feature extractors. Experimental results demonstrate that VoT scales effectively with larger datasets, benefits substantially from stronger pre-trained backbones, generalizes across diverse camera motions and calibration settings, and outperforms traditional methods while running more than 3 times faster. |
 | Ana Manzano Rodriguez, Cees G M Snoek, Marlies P Schijven: Bridging the Gap: Exposing the Hidden Challenges Towards Adoption of Artificial Intelligence in Surgery. In: BJS, vol. 112, iss. 11, 2025. @article{RodriguezBJS25,
title = {Bridging the Gap: Exposing the Hidden Challenges Towards Adoption of Artificial Intelligence in Surgery},
author = {Ana Manzano Rodriguez and Cees G M Snoek and Marlies P Schijven},
url = {https://doi.org/10.1093/bjs/znaf217},
year = {2025},
date = {2025-09-09},
urldate = {2025-09-09},
journal = {BJS},
volume = {112},
issue = {11},
abstract = {Bridging the gap between AI research and surgery is essential for reaping the benefits AI can bring to surgical practice. The path forward is clear: fostering better collaboration between these very different fields of expertise. Only through collective action can surgical AI move beyond isolated studies towards meaningful advancements creating a true ecosystem. With well-defined standards, the field can evolve faster, achieving the significant advances we are all expecting. The potential is immense, but without structured cooperation, it will remain unrealized. Now is the time for our disciplines to unite, plan and deliver.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Bridging the gap between AI research and surgery is essential for reaping the benefits AI can bring to surgical practice. The path forward is clear: fostering better collaboration between these very different fields of expertise. Only through collective action can surgical AI move beyond isolated studies towards meaningful advancements creating a true ecosystem. With well-defined standards, the field can evolve faster, achieving the significant advances we are all expecting. The potential is immense, but without structured cooperation, it will remain unrealized. Now is the time for our disciplines to unite, plan and deliver. |
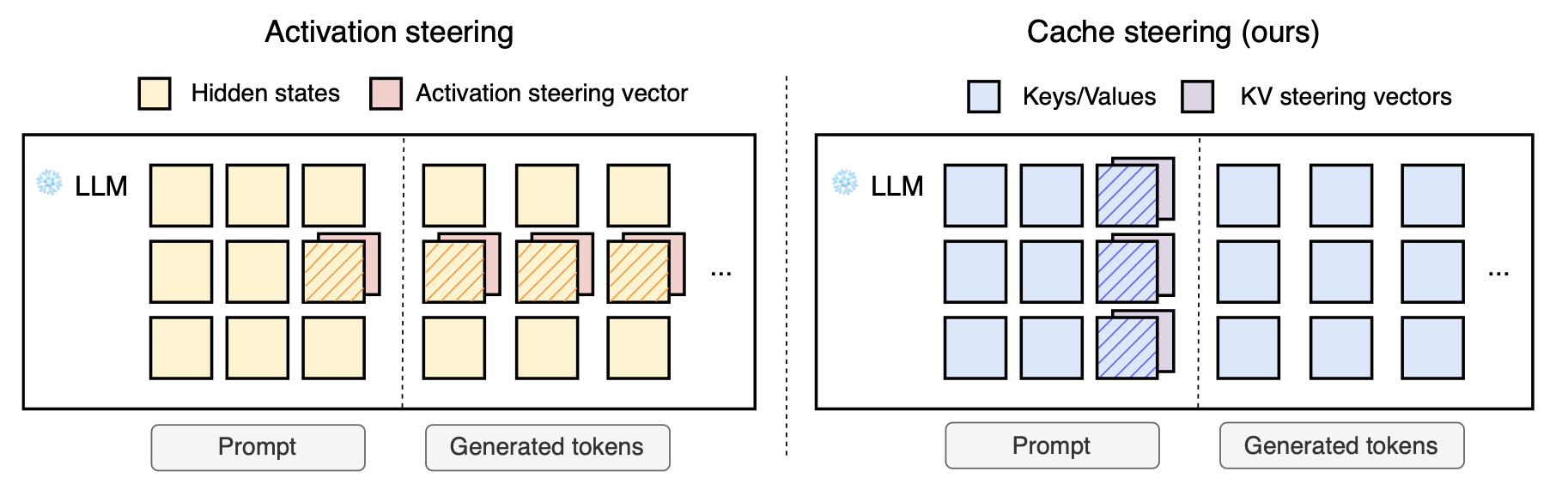 | Max Belitsky, Dawid J Kopiczko, Michael Dorkenwald, M. Jehanzeb Mirza, Cees G M Snoek, Yuki M Asano: KV Cache Steering for Controlling Frozen LLMs. arXiv:2507.08799, 2025. @unpublished{BelitskyArxiv2025,
title = {KV Cache Steering for Controlling Frozen LLMs},
author = {Max Belitsky and Dawid J Kopiczko and Michael Dorkenwald and M. Jehanzeb Mirza and Cees G M Snoek and Yuki M Asano},
url = {https://arxiv.org/abs/2507.08799},
year = {2025},
date = {2025-07-11},
urldate = {2025-07-11},
abstract = {We propose cache steering, a lightweight method for implicit steering of language models via a one-shot intervention applied directly to the key-value cache. To validate its effectiveness, we apply cache steering to induce chain-of-thought reasoning in small language models. Our approach leverages GPT-4o-generated reasoning traces to construct steering vectors that shift model behavior toward more explicit, multi-step reasoning without fine-tuning or prompt modifications. Experimental evaluations on diverse reasoning benchmarks demonstrate that cache steering improves both the qualitative structure of model reasoning and quantitative task performance. Compared to prior activation steering techniques that require continuous interventions, our one-shot cache steering offers substantial advantages in terms of hyperparameter stability, inference-time efficiency, and ease of integration, making it a more robust and practical solution for controlled generation.},
howpublished = {arXiv:2507.08799},
keywords = {},
pubstate = {published},
tppubtype = {unpublished}
}
We propose cache steering, a lightweight method for implicit steering of language models via a one-shot intervention applied directly to the key-value cache. To validate its effectiveness, we apply cache steering to induce chain-of-thought reasoning in small language models. Our approach leverages GPT-4o-generated reasoning traces to construct steering vectors that shift model behavior toward more explicit, multi-step reasoning without fine-tuning or prompt modifications. Experimental evaluations on diverse reasoning benchmarks demonstrate that cache steering improves both the qualitative structure of model reasoning and quantitative task performance. Compared to prior activation steering techniques that require continuous interventions, our one-shot cache steering offers substantial advantages in terms of hyperparameter stability, inference-time efficiency, and ease of integration, making it a more robust and practical solution for controlled generation. |
 | Mohammad Mahdi Derakhshani, Dheeraj Varghese, Marzieh Fadaee, Cees G M Snoek: NeoBabel: A Multilingual Open Tower for Visual Generation. arXiv:2507.06137, 2025. @unpublished{DerakhshaniArxiv2025,
title = {NeoBabel: A Multilingual Open Tower for Visual Generation},
author = {Mohammad Mahdi Derakhshani and Dheeraj Varghese and Marzieh Fadaee and Cees G M Snoek},
url = {https://arxiv.org/abs/2507.06137
https://neo-babel.github.io},
year = {2025},
date = {2025-07-08},
urldate = {2025-07-08},
abstract = {Text-to-image generation advancements have been predominantly English-centric, creating barriers for non-English speakers and perpetuating digital inequities. While existing systems rely on translation pipelines, these introduce semantic drift, computational overhead, and cultural misalignment. We introduce NeoBabel, a novel multilingual image generation framework that sets a new Pareto frontier in performance, efficiency and inclusivity, supporting six languages: English, Chinese, Dutch, French, Hindi, and Persian. The model is trained using a combination of large-scale multilingual pretraining and high-resolution instruction tuning. To evaluate its capabilities, we expand two English-only benchmarks to multilingual equivalents: m-GenEval and m-DPG. NeoBabel achieves state-of-the-art multilingual performance while retaining strong English capability, scoring 0.75 on m-GenEval and 0.68 on m-DPG. Notably, it performs on par with leading models on English tasks while outperforming them by +0.11 and +0.09 on multilingual benchmarks, even though these models are built on multilingual base LLMs. This demonstrates the effectiveness of our targeted alignment training for preserving and extending crosslingual generalization. We further introduce two new metrics to rigorously assess multilingual alignment and robustness to code-mixed prompts. Notably, NeoBabel matches or exceeds English-only models while being 2-4x smaller. We release an open toolkit, including all code, model checkpoints, a curated dataset of 124M multilingual text-image pairs, and standardized multilingual evaluation protocols, to advance inclusive AI research. Our work demonstrates that multilingual capability is not a trade-off but a catalyst for improved robustness, efficiency, and cultural fidelity in generative AI.},
howpublished = {arXiv:2507.06137},
keywords = {},
pubstate = {published},
tppubtype = {unpublished}
}
Text-to-image generation advancements have been predominantly English-centric, creating barriers for non-English speakers and perpetuating digital inequities. While existing systems rely on translation pipelines, these introduce semantic drift, computational overhead, and cultural misalignment. We introduce NeoBabel, a novel multilingual image generation framework that sets a new Pareto frontier in performance, efficiency and inclusivity, supporting six languages: English, Chinese, Dutch, French, Hindi, and Persian. The model is trained using a combination of large-scale multilingual pretraining and high-resolution instruction tuning. To evaluate its capabilities, we expand two English-only benchmarks to multilingual equivalents: m-GenEval and m-DPG. NeoBabel achieves state-of-the-art multilingual performance while retaining strong English capability, scoring 0.75 on m-GenEval and 0.68 on m-DPG. Notably, it performs on par with leading models on English tasks while outperforming them by +0.11 and +0.09 on multilingual benchmarks, even though these models are built on multilingual base LLMs. This demonstrates the effectiveness of our targeted alignment training for preserving and extending crosslingual generalization. We further introduce two new metrics to rigorously assess multilingual alignment and robustness to code-mixed prompts. Notably, NeoBabel matches or exceeds English-only models while being 2-4x smaller. We release an open toolkit, including all code, model checkpoints, a curated dataset of 124M multilingual text-image pairs, and standardized multilingual evaluation protocols, to advance inclusive AI research. Our work demonstrates that multilingual capability is not a trade-off but a catalyst for improved robustness, efficiency, and cultural fidelity in generative AI. |
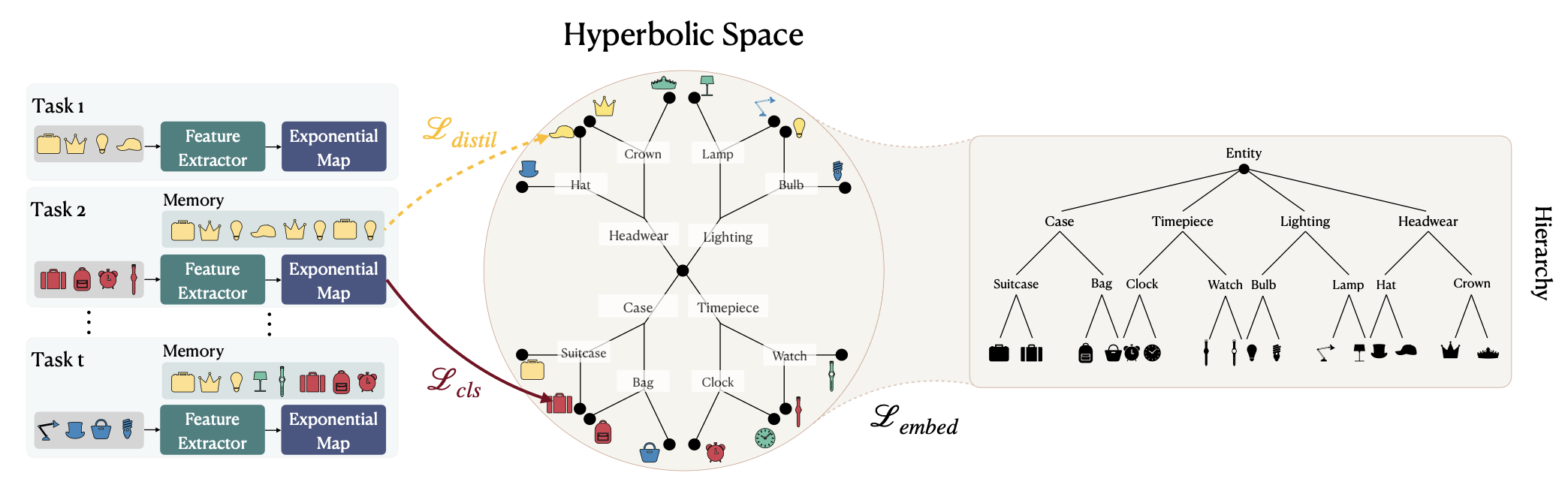 | Melika Ayoughi, Mina Ghadimi Atigh, Mohammad Mahdi Derakhshani, Cees G M Snoek, Pascal Mettes, Paul Groth: Continual Hyperbolic Learning of Instances and Classes. arXiv:2506.10710, 2025. @unpublished{ayoughiArxiv2025,
title = {Continual Hyperbolic Learning of Instances and Classes},
author = {Melika Ayoughi and Mina Ghadimi Atigh and Mohammad Mahdi Derakhshani and Cees G M Snoek and Pascal Mettes and Paul Groth},
url = {https://arxiv.org/abs/2506.10710},
year = {2025},
date = {2025-06-12},
urldate = {2025-06-12},
howpublished = {arXiv:2506.10710},
keywords = {},
pubstate = {published},
tppubtype = {unpublished}
}
|
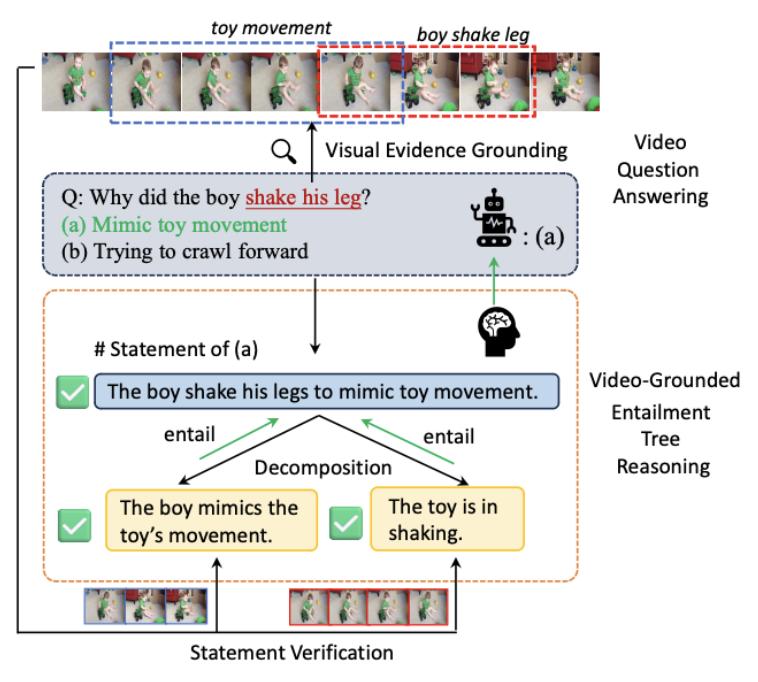 | Huabin Liu, Filip Ilievski, Cees G M Snoek: Commonsense Video Question Answering through Video-Grounded Entailment Tree Reasoning. In: CVPR, 2025. @inproceedings{LiuCVPR2025,
title = {Commonsense Video Question Answering through Video-Grounded Entailment Tree Reasoning},
author = {Huabin Liu and Filip Ilievski and Cees G M Snoek},
url = {https://arxiv.org/abs/2501.05069},
year = {2025},
date = {2025-06-11},
urldate = {2025-01-09},
booktitle = {CVPR},
abstract = {This paper proposes the first video-grounded entailment tree reasoning method for commonsense video question answering (VQA). Despite the remarkable progress of large visual-language models (VLMs), there are growing concerns that they learn spurious correlations between videos and likely answers, reinforced by their black-box nature and remaining benchmarking biases. Our method explicitly grounds VQA tasks to video fragments in four steps: entailment tree construction, video-language entailment verification, tree reasoning, and dynamic tree expansion. A vital benefit of the method is its generalizability to current video and image-based VLMs across reasoning types. To support fair evaluation, we devise a de-biasing procedure based on large-language models that rewrites VQA benchmark answer sets to enforce model reasoning. Systematic experiments on existing and de-biased benchmarks highlight the impact of our method components across benchmarks, VLMs, and reasoning types.},
howpublished = {arXiv:2501.05069},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
This paper proposes the first video-grounded entailment tree reasoning method for commonsense video question answering (VQA). Despite the remarkable progress of large visual-language models (VLMs), there are growing concerns that they learn spurious correlations between videos and likely answers, reinforced by their black-box nature and remaining benchmarking biases. Our method explicitly grounds VQA tasks to video fragments in four steps: entailment tree construction, video-language entailment verification, tree reasoning, and dynamic tree expansion. A vital benefit of the method is its generalizability to current video and image-based VLMs across reasoning types. To support fair evaluation, we devise a de-biasing procedure based on large-language models that rewrites VQA benchmark answer sets to enforce model reasoning. Systematic experiments on existing and de-biased benchmarks highlight the impact of our method components across benchmarks, VLMs, and reasoning types. |
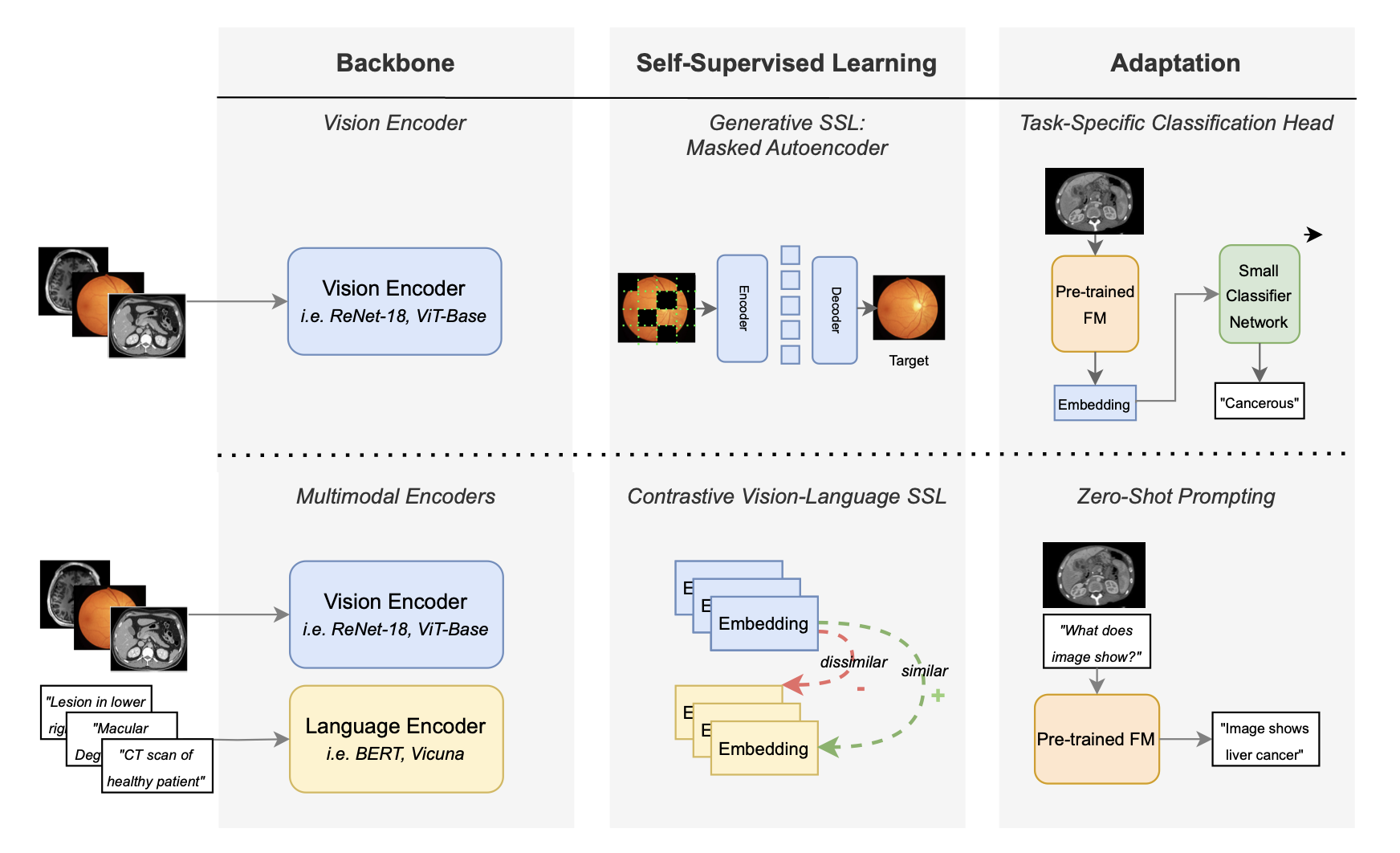 | Vivien van Veldhuizen, Vanessa Botha, Chunyao Lu, Melis Erdal Cesur, Kevin Groot Lipman, Edwin D de Jong, Hugo Horlings, Clárisa I Sanchez, Cees G M Snoek, Lodewyk Wessels, Ritse Mann, Eric Marcus, Jonas Teuwen: Foundation Models in Medical Imaging -- A Review and Outlook. arXiv:2506.09095, 2025. @unpublished{veldhuizenArxiv2025,
title = {Foundation Models in Medical Imaging -- A Review and Outlook},
author = {Vivien van Veldhuizen and Vanessa Botha and Chunyao Lu and Melis Erdal Cesur and Kevin Groot Lipman and Edwin D de Jong and Hugo Horlings and Clárisa I Sanchez and Cees G M Snoek and Lodewyk Wessels and Ritse Mann and Eric Marcus and Jonas Teuwen},
url = {https://arxiv.org/abs/2506.09095},
year = {2025},
date = {2025-06-10},
urldate = {2025-06-10},
howpublished = {arXiv:2506.09095},
keywords = {},
pubstate = {published},
tppubtype = {unpublished}
}
|
 | Aritra Bhowmik, Pascal Mettes, Martin R Oswald, Cees G M Snoek: Union-over-Intersections: Object Detection beyond Winner-Takes-All. In: ICLR, 2025, (Spotlight presentation). @inproceedings{BhowmikICLR2025,
title = {Union-over-Intersections: Object Detection beyond Winner-Takes-All},
author = {Aritra Bhowmik and Pascal Mettes and Martin R Oswald and Cees G M Snoek},
url = {https://openreview.net/pdf?id=HqLHY4TzGj},
year = {2025},
date = {2025-04-24},
urldate = {2025-04-24},
booktitle = {ICLR},
abstract = {This paper revisits the problem of predicting box locations in object detection architectures. Typically, each box proposal or box query aims to directly maximize the intersection-over-union score with the ground truth, followed by a winner-takes-all non-maximum suppression where only the highest scoring box in each region is retained. We observe that both steps are sub-optimal: the first involves regressing proposals to the entire ground truth, which is a difficult task even with large receptive fields, and the second neglects valuable information from boxes other than the top candidate. Instead of regressing proposals to the whole ground truth, we propose a simpler approach: regress only to the area of intersection between the proposal and the ground truth. This avoids the need for proposals to extrapolate beyond their visual scope, improving localization accuracy. Rather than adopting a winner-takes-all strategy, we take the union over the regressed intersections of all boxes in a region to generate the final box outputs. Our plug-and-play method integrates seamlessly into proposal-based, grid-based, and query-based detection architectures with minimal modifications, consistently improving object localization and instance segmentation. We demonstrate its broad applicability and versatility across various detection and segmentation tasks.},
howpublished = {arXiv:2311.18512},
note = {Spotlight presentation},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
This paper revisits the problem of predicting box locations in object detection architectures. Typically, each box proposal or box query aims to directly maximize the intersection-over-union score with the ground truth, followed by a winner-takes-all non-maximum suppression where only the highest scoring box in each region is retained. We observe that both steps are sub-optimal: the first involves regressing proposals to the entire ground truth, which is a difficult task even with large receptive fields, and the second neglects valuable information from boxes other than the top candidate. Instead of regressing proposals to the whole ground truth, we propose a simpler approach: regress only to the area of intersection between the proposal and the ground truth. This avoids the need for proposals to extrapolate beyond their visual scope, improving localization accuracy. Rather than adopting a winner-takes-all strategy, we take the union over the regressed intersections of all boxes in a region to generate the final box outputs. Our plug-and-play method integrates seamlessly into proposal-based, grid-based, and query-based detection architectures with minimal modifications, consistently improving object localization and instance segmentation. We demonstrate its broad applicability and versatility across various detection and segmentation tasks. |
 | Duy-Kien Nguyen, Mahmoud Assran, Unnat Jain, Martin R Oswald, Cees G M Snoek, Xinlei Chen: An Image is Worth More Than 16x16 Patches: Exploring Transformers on Individual Pixels. In: ICLR, 2025. @inproceedings{NguyenICLR2025,
title = {An Image is Worth More Than 16x16 Patches: Exploring Transformers on Individual Pixels},
author = {Duy-Kien Nguyen and Mahmoud Assran and Unnat Jain and Martin R Oswald and Cees G M Snoek and Xinlei Chen},
url = {https://arxiv.org/abs/2406.09415},
year = {2025},
date = {2025-04-24},
urldate = {2024-06-13},
booktitle = {ICLR},
abstract = {This work does not introduce a new method. Instead, we present an interesting finding that questions the necessity of the inductive bias -- locality in modern computer vision architectures. Concretely, we find that vanilla Transformers can operate by directly treating each individual pixel as a token and achieve highly performant results. This is substantially different from the popular design in Vision Transformer, which maintains the inductive bias from ConvNets towards local neighborhoods (e.g. by treating each 16x16 patch as a token). We mainly showcase the effectiveness of pixels-as-tokens across three well-studied tasks in computer vision: supervised learning for object classification, self-supervised learning via masked autoencoding, and image generation with diffusion models. Although directly operating on individual pixels is less computationally practical, we believe the community must be aware of this surprising piece of knowledge when devising the next generation of neural architectures for computer vision.},
howpublished = {arXiv:2406.09415},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
This work does not introduce a new method. Instead, we present an interesting finding that questions the necessity of the inductive bias -- locality in modern computer vision architectures. Concretely, we find that vanilla Transformers can operate by directly treating each individual pixel as a token and achieve highly performant results. This is substantially different from the popular design in Vision Transformer, which maintains the inductive bias from ConvNets towards local neighborhoods (e.g. by treating each 16x16 patch as a token). We mainly showcase the effectiveness of pixels-as-tokens across three well-studied tasks in computer vision: supervised learning for object classification, self-supervised learning via masked autoencoding, and image generation with diffusion models. Although directly operating on individual pixels is less computationally practical, we believe the community must be aware of this surprising piece of knowledge when devising the next generation of neural architectures for computer vision. |
 | Ivona Najdenkoska, Mohammad Mahdi Derakhshani, Yuki M Asano, Nanne van Noord, Marcel Worring, Cees G M Snoek
: TULIP: Token-length Upgraded CLIP. In: ICLR, 2025. @inproceedings{NajdenkoskaICLR25,
title = {TULIP: Token-length Upgraded CLIP},
author = {Ivona Najdenkoska and Mohammad Mahdi Derakhshani and Yuki M Asano and Nanne van Noord and Marcel Worring and Cees G M Snoek
},
url = {https://arxiv.org/abs/2410.10034},
year = {2025},
date = {2025-04-24},
urldate = {2024-10-13},
booktitle = {ICLR},
abstract = {We address the challenge of representing long captions in vision-language models, such as CLIP. By design these models are limited by fixed, absolute positional encodings, restricting inputs to a maximum of 77 tokens and hindering performance on tasks requiring longer descriptions. Although recent work has attempted to overcome this limit, their proposed approaches struggle to model token relationships over longer distances and simply extend to a fixed new token length. Instead, we propose a generalizable method, named TULIP, able to upgrade the token length to any length for CLIP-like models. We do so by improving the architecture with relative position encodings, followed by a training procedure that (i) distills the original CLIP text encoder into an encoder with relative position encodings and (ii) enhances the model for aligning longer captions with images. By effectively encoding captions longer than the default 77 tokens, our model outperforms baselines on cross-modal tasks such as retrieval and text-to-image generation.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
We address the challenge of representing long captions in vision-language models, such as CLIP. By design these models are limited by fixed, absolute positional encodings, restricting inputs to a maximum of 77 tokens and hindering performance on tasks requiring longer descriptions. Although recent work has attempted to overcome this limit, their proposed approaches struggle to model token relationships over longer distances and simply extend to a fixed new token length. Instead, we propose a generalizable method, named TULIP, able to upgrade the token length to any length for CLIP-like models. We do so by improving the architecture with relative position encodings, followed by a training procedure that (i) distills the original CLIP text encoder into an encoder with relative position encodings and (ii) enhances the model for aligning longer captions with images. By effectively encoding captions longer than the default 77 tokens, our model outperforms baselines on cross-modal tasks such as retrieval and text-to-image generation. |
 | Christina Sartzetaki, Gemma Roig, Cees G M Snoek, Iris I A Groen: One Hundred Neural Networks and Brains Watching Videos: Lessons from Alignment. In: ICLR, 2025. @inproceedings{SartzetakiICLR2025,
title = {One Hundred Neural Networks and Brains Watching Videos: Lessons from Alignment},
author = {Christina Sartzetaki and Gemma Roig and Cees G M Snoek and Iris I A Groen},
url = {https://openreview.net/pdf?id=LM4PYXBId5},
year = {2025},
date = {2025-04-24},
urldate = {2025-04-24},
booktitle = {ICLR},
abstract = {What can we learn from comparing video models to human brains, arguably the most efficient and effective video processing systems in existence? Our work takes a step towards answering this question by performing the first large-scale benchmarking of deep video models on representational alignment to the human brain, using publicly available models and a recently released video brain imaging (fMRI) dataset. We disentangle four factors of variation in the models (temporal modeling, classification task, architecture, and training dataset) that affect alignment to the brain, which we measure by conducting Representational Similarity Analysis across multiple brain regions and model layers. We show that temporal modeling is key for alignment to brain regions involved in early visual processing, while a relevant classification task is key for alignment to higher-level regions. Moreover, we identify clear differences between the brain scoring patterns across layers of CNNs and Transformers, and reveal how training dataset biases transfer to alignment with functionally selective brain areas. Additionally, we uncover a negative correlation of computational complexity to brain alignment. Measuring a total of 99 neural networks and 10 human brains watching videos, we aim to forge a path that widens our understanding of temporal and semantic video representations in brains and machines, ideally leading towards more efficient video models and more mechanistic explanations of processing in the human brain.},
howpublished = {bioRxiv 2024.12.05.626975},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
What can we learn from comparing video models to human brains, arguably the most efficient and effective video processing systems in existence? Our work takes a step towards answering this question by performing the first large-scale benchmarking of deep video models on representational alignment to the human brain, using publicly available models and a recently released video brain imaging (fMRI) dataset. We disentangle four factors of variation in the models (temporal modeling, classification task, architecture, and training dataset) that affect alignment to the brain, which we measure by conducting Representational Similarity Analysis across multiple brain regions and model layers. We show that temporal modeling is key for alignment to brain regions involved in early visual processing, while a relevant classification task is key for alignment to higher-level regions. Moreover, we identify clear differences between the brain scoring patterns across layers of CNNs and Transformers, and reveal how training dataset biases transfer to alignment with functionally selective brain areas. Additionally, we uncover a negative correlation of computational complexity to brain alignment. Measuring a total of 99 neural networks and 10 human brains watching videos, we aim to forge a path that widens our understanding of temporal and semantic video representations in brains and machines, ideally leading towards more efficient video models and more mechanistic explanations of processing in the human brain. |
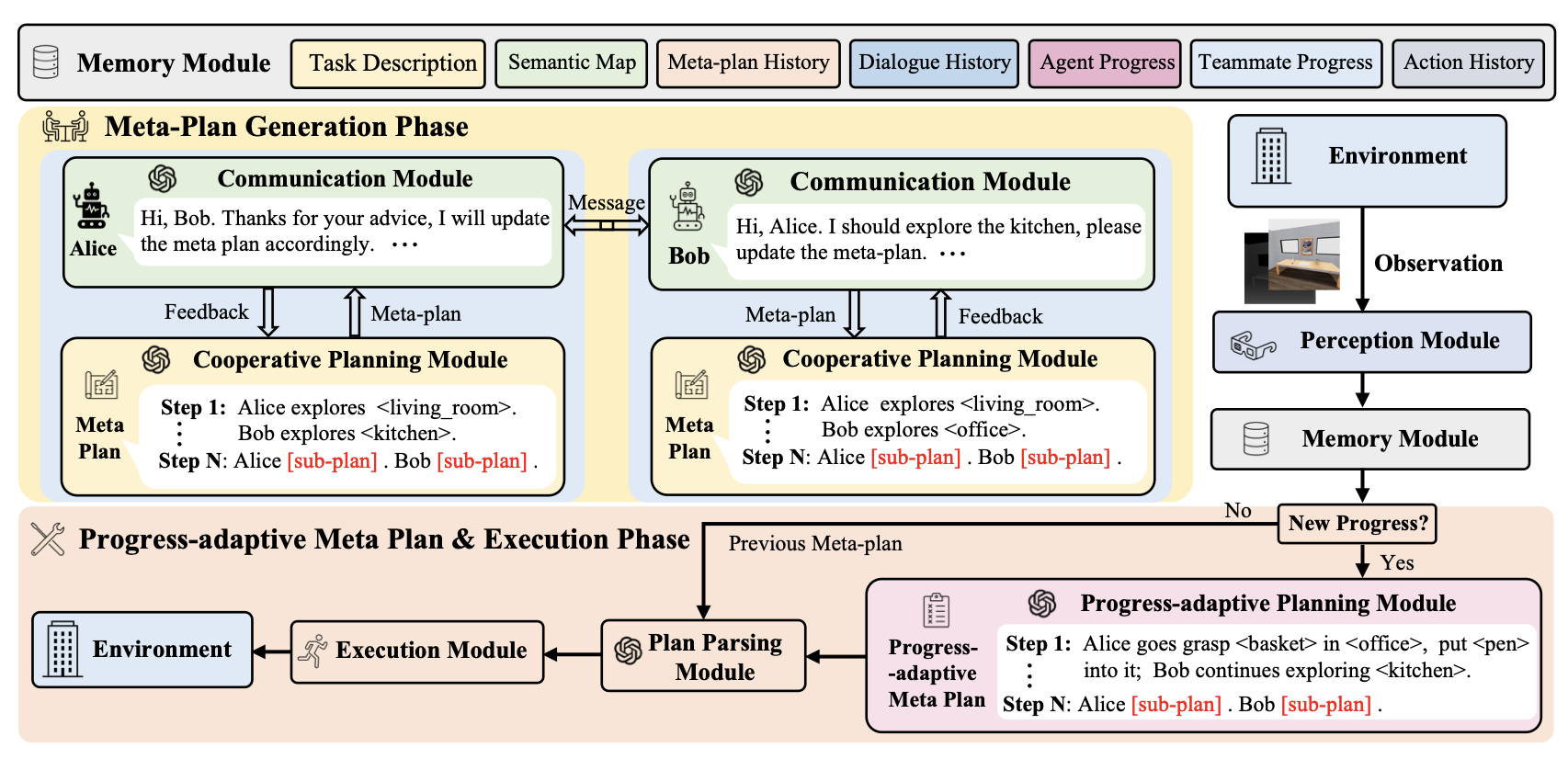 | Jie Liu, Pan Zhou, Yingjun Du, Ah-Hwee Tan, Cees G M Snoek, Jan-Jakob Sonke, Efstratios Gavves: CaPo: Cooperative Plan Optimization for Efficient Embodied Multi-Agent Cooperation. In: ICLR, 2025. @inproceedings{LiuICLR2025,
title = {CaPo: Cooperative Plan Optimization for Efficient Embodied Multi-Agent Cooperation},
author = {Jie Liu and Pan Zhou and Yingjun Du and Ah-Hwee Tan and Cees G M Snoek and Jan-Jakob Sonke and Efstratios Gavves},
url = {https://arxiv.org/abs/2411.04679},
year = {2025},
date = {2025-04-24},
booktitle = {ICLR},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
|
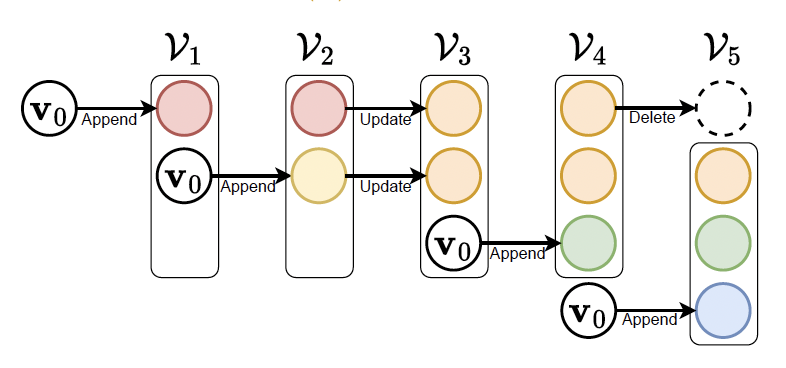 | Zehao Xiao, Shilin Yan, Jack Hong, Jiayin Cai, Xiaolong Jiang, Yao Hu, Jiayi Shen, Cheems Wang, Cees G M Snoek: DynaPrompt: Dynamic Test-Time Prompt Tuning. In: ICLR, 2025. @inproceedings{XiaoICLR2025,
title = {DynaPrompt: Dynamic Test-Time Prompt Tuning},
author = {Zehao Xiao and Shilin Yan and Jack Hong and Jiayin Cai and Xiaolong Jiang and Yao Hu and Jiayi Shen and Cheems Wang and Cees G M Snoek},
url = {https://github.com/zzzx1224/DynaPrompt
https://arxiv.org/abs/2501.16404},
year = {2025},
date = {2025-04-24},
urldate = {2025-04-24},
booktitle = {ICLR},
abstract = {Test-time prompt tuning enhances zero-shot generalization of vision-language models but tends to ignore the relatedness among test samples during inference. Online test-time prompt tuning provides a simple way to leverage the information in previous test samples, albeit with the risk of prompt collapse due to error accumulation. To enhance test-time prompt tuning, we propose DynaPrompt, short for dynamic test-time prompt tuning, exploiting relevant data distribution information while reducing error accumulation. Built on an online prompt buffer, DynaPrompt adaptively selects and optimizes the relevant prompts for each test sample during tuning. Specifically, we introduce a dynamic prompt selection strategy based on two metrics: prediction entropy and probability difference. For unseen test data information, we develop dynamic prompt appending, which allows the buffer to append new prompts and delete the inactive ones. By doing so, the prompts are optimized to exploit beneficial information on specific test data, while alleviating error accumulation. Experiments on fourteen datasets demonstrate the effectiveness of dynamic test-time prompt tuning.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Test-time prompt tuning enhances zero-shot generalization of vision-language models but tends to ignore the relatedness among test samples during inference. Online test-time prompt tuning provides a simple way to leverage the information in previous test samples, albeit with the risk of prompt collapse due to error accumulation. To enhance test-time prompt tuning, we propose DynaPrompt, short for dynamic test-time prompt tuning, exploiting relevant data distribution information while reducing error accumulation. Built on an online prompt buffer, DynaPrompt adaptively selects and optimizes the relevant prompts for each test sample during tuning. Specifically, we introduce a dynamic prompt selection strategy based on two metrics: prediction entropy and probability difference. For unseen test data information, we develop dynamic prompt appending, which allows the buffer to append new prompts and delete the inactive ones. By doing so, the prompts are optimized to exploit beneficial information on specific test data, while alleviating error accumulation. Experiments on fourteen datasets demonstrate the effectiveness of dynamic test-time prompt tuning. |
 | Lasse Suonperä Liebst, Wim Bernasco, Peter Ejbye-Ernst, Nigel van Herwijnen, Thomas van der Veen, Dennis Koelma, Cees G M Snoek, Marie Rosenkrantz Lindegaard: Association Between Social Distancing Compliance and Public Place Crowding During the COVID-19 Pandemic: Cross-Sectional Observational Study Using Computer Vision to Analyze Surveillance Footage. In: JMIR Public Health and Surveillance, vol. 11, 2025, ISBN: 2369-2960. @article{LiebstJMIR2025,
title = {Association Between Social Distancing Compliance and Public Place Crowding During the COVID-19 Pandemic: Cross-Sectional Observational Study Using Computer Vision to Analyze Surveillance Footage},
author = {Lasse Suonperä Liebst and Wim Bernasco and Peter Ejbye-Ernst and Nigel van Herwijnen and Thomas van der Veen and Dennis Koelma and Cees G M Snoek and Marie Rosenkrantz Lindegaard},
url = {https://publichealth.jmir.org/2025/1/e50929},
doi = {10.2196/50929},
isbn = {2369-2960},
year = {2025},
date = {2025-04-17},
urldate = {2025-04-17},
journal = {JMIR Public Health and Surveillance},
volume = {11},
abstract = {Background:
Social distancing behavior has been a critical nonpharmaceutical measure for mitigating the COVID-19 pandemic. For this reason, there has been widespread interest in the factors determining social distancing violations, with a particular focus on individual-based factors.
Objective:
In this paper, we examine an alternative and less appreciated indicator of social distancing violations: the situational opportunity for maintaining interpersonal distance in crowded settings. This focus on situational opportunities is borrowed from criminology, where it offers an alternative to individual-based explanations of crime and rule violations. We extend this approach to the COVID-19 pandemic context, suggesting its relevance in understanding distancing compliance behavior.
Methods:
Our data comprise a large collection of video clips (n=56,429) from public places in Amsterdam, the Netherlands, captured by municipal surveillance cameras throughout the first year of the pandemic. We automatized the analysis of this footage using a computer vision algorithm designed for pedestrian detection and estimation of metric distances between individuals in the video still frames. This method allowed us to record social distancing violations of over half a million individuals (n=539,127) across more and less crowded street contexts.
Results:
The data revealed a clear positive association between crowding and social distancing violations, evident both at the individual level and when aggregated per still frame. At the individual level, the analysis estimated that each additional 10 people present increased the likelihood of a distancing violation by 9 percentage points for a given pedestrian. At the aggregated level, there was an estimated increase of approximately 6 additional violations for every 10 additional individuals present, with a very large R² of 0.80. Additionally, a comparison with simulation data indicated that street spaces should, in principle, provide sufficient room for people to pass each other while maintaining a 1.5-meter distance. This suggests that pedestrians tend to gravitate toward others, even when ample space exists to maintain distance.
Conclusions:
The direct positive relationship between crowding and distancing violations suggests that potential transmission encounters can be identified by simply counting the number of people present in a location. Our findings thus provide a reliable and scalable proxy measure of distancing noncompliance that offers epidemiologists a tool to easily incorporate real-life behavior into predictive models of airborne contagious diseases. Furthermore, our results highlight the need for scholars and public health agencies to consider the situational factors influencing social distancing violations, especially those related to crowding in public settings.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Background:
Social distancing behavior has been a critical nonpharmaceutical measure for mitigating the COVID-19 pandemic. For this reason, there has been widespread interest in the factors determining social distancing violations, with a particular focus on individual-based factors.
Objective:
In this paper, we examine an alternative and less appreciated indicator of social distancing violations: the situational opportunity for maintaining interpersonal distance in crowded settings. This focus on situational opportunities is borrowed from criminology, where it offers an alternative to individual-based explanations of crime and rule violations. We extend this approach to the COVID-19 pandemic context, suggesting its relevance in understanding distancing compliance behavior.
Methods:
Our data comprise a large collection of video clips (n=56,429) from public places in Amsterdam, the Netherlands, captured by municipal surveillance cameras throughout the first year of the pandemic. We automatized the analysis of this footage using a computer vision algorithm designed for pedestrian detection and estimation of metric distances between individuals in the video still frames. This method allowed us to record social distancing violations of over half a million individuals (n=539,127) across more and less crowded street contexts.
Results:
The data revealed a clear positive association between crowding and social distancing violations, evident both at the individual level and when aggregated per still frame. At the individual level, the analysis estimated that each additional 10 people present increased the likelihood of a distancing violation by 9 percentage points for a given pedestrian. At the aggregated level, there was an estimated increase of approximately 6 additional violations for every 10 additional individuals present, with a very large R² of 0.80. Additionally, a comparison with simulation data indicated that street spaces should, in principle, provide sufficient room for people to pass each other while maintaining a 1.5-meter distance. This suggests that pedestrians tend to gravitate toward others, even when ample space exists to maintain distance.
Conclusions:
The direct positive relationship between crowding and distancing violations suggests that potential transmission encounters can be identified by simply counting the number of people present in a location. Our findings thus provide a reliable and scalable proxy measure of distancing noncompliance that offers epidemiologists a tool to easily incorporate real-life behavior into predictive models of airborne contagious diseases. Furthermore, our results highlight the need for scholars and public health agencies to consider the situational factors influencing social distancing violations, especially those related to crowding in public settings. |
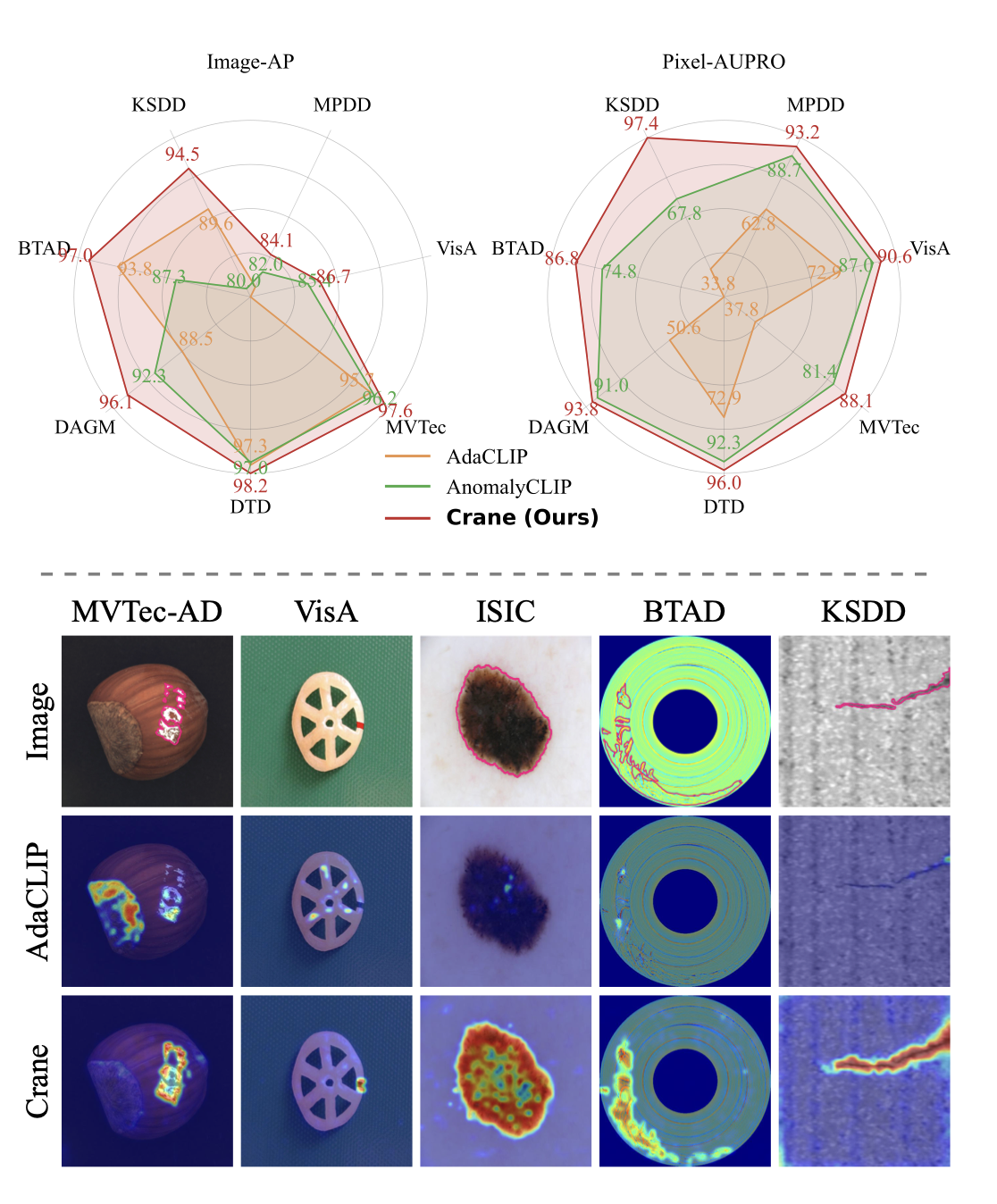 | Alireza Salehi, Mohammadreza Salehi, Reshad Hosseini, Cees G M Snoek, Makoto Yamada, Mohammad Sabokrou: Crane: Context-Guided Prompt Learning and Attention Refinement for Zero-Shot Anomaly Detections. arXiv:2504.11055, 2025. @unpublished{SalehiArxiv2025,
title = {Crane: Context-Guided Prompt Learning and Attention Refinement for Zero-Shot Anomaly Detections},
author = {Alireza Salehi and Mohammadreza Salehi and Reshad Hosseini and Cees G M Snoek and Makoto Yamada and Mohammad Sabokrou},
url = {https://arxiv.org/abs/2504.11055},
year = {2025},
date = {2025-04-15},
abstract = {Anomaly Detection (AD) involves identifying deviations from normal data distributions and is critical in fields such as medical diagnostics and industrial defect detection. Traditional AD methods typically require the availability of normal training samples; however, this assumption is not always feasible, as collecting such data can be impractical. Additionally, these methods often struggle to generalize across different domains. Recent advancements, such as AnomalyCLIP and AdaCLIP, utilize the zero-shot generalization capabilities of CLIP but still face a performance gap between image-level and pixel-level anomaly detection. To address this gap, we propose a novel approach that conditions the prompts of the text encoder based on image context extracted from the vision encoder. Also, to capture fine-grained variations more effectively, we have modified the CLIP vision encoder and altered the extraction of dense features. These changes ensure that the features retain richer spatial and structural information for both normal and anomalous prompts. Our method achieves state-of-the-art performance, improving performance by 2% to 29% across different metrics on 14 datasets. This demonstrates its effectiveness in both image-level and pixel-level anomaly detection.},
howpublished = {arXiv:2504.11055},
keywords = {},
pubstate = {published},
tppubtype = {unpublished}
}
Anomaly Detection (AD) involves identifying deviations from normal data distributions and is critical in fields such as medical diagnostics and industrial defect detection. Traditional AD methods typically require the availability of normal training samples; however, this assumption is not always feasible, as collecting such data can be impractical. Additionally, these methods often struggle to generalize across different domains. Recent advancements, such as AnomalyCLIP and AdaCLIP, utilize the zero-shot generalization capabilities of CLIP but still face a performance gap between image-level and pixel-level anomaly detection. To address this gap, we propose a novel approach that conditions the prompts of the text encoder based on image context extracted from the vision encoder. Also, to capture fine-grained variations more effectively, we have modified the CLIP vision encoder and altered the extraction of dense features. These changes ensure that the features retain richer spatial and structural information for both normal and anomalous prompts. Our method achieves state-of-the-art performance, improving performance by 2% to 29% across different metrics on 14 datasets. This demonstrates its effectiveness in both image-level and pixel-level anomaly detection. |
 | Piyush Bagad, Makarand Tapaswi, Cees G M Snoek, Andrew Zisserman: The Sound of Water: Inferring Physical Properties from Pouring Liquids. In: ICASSP, 2025. @inproceedings{BagadICASSP2025,
title = {The Sound of Water: Inferring Physical Properties from Pouring Liquids},
author = {Piyush Bagad and Makarand Tapaswi and Cees G M Snoek and Andrew Zisserman},
url = {https://bpiyush.github.io/pouring-water-website/
https://huggingface.co/spaces/bpiyush/SoundOfWater
https://www.youtube.com/watch?v=Yq1Ic0GXeiM
https://arxiv.org/abs/2411.11222},
year = {2025},
date = {2025-04-06},
urldate = {2025-04-06},
booktitle = {ICASSP},
abstract = {We study the connection between audio-visual observations and the underlying physics of a mundane yet intriguing everyday activity: pouring liquids. Given only the sound of liquid pouring into a container, our objective is to automatically infer physical properties such as the liquid level, the shape and size of the container, the pouring rate and the time to fill. To this end, we: (i) show in theory that these properties can be determined from the fundamental frequency (pitch); (ii) train a pitch detection model with supervision from simulated data and visual data with a physics-inspired objective; (iii) introduce a new large dataset of real pouring videos for a systematic study; (iv) show that the trained model can indeed infer these physical properties for real data; and finally, (v) we demonstrate strong generalization to various container shapes, other datasets, and in-the-wild YouTube videos. Our work presents a keen understanding of a narrow yet rich problem at the intersection of acoustics, physics, and learning. It opens up applications to enhance multisensory perception in robotic pouring.},
howpublished = {arXiv:2411.11222},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
We study the connection between audio-visual observations and the underlying physics of a mundane yet intriguing everyday activity: pouring liquids. Given only the sound of liquid pouring into a container, our objective is to automatically infer physical properties such as the liquid level, the shape and size of the container, the pouring rate and the time to fill. To this end, we: (i) show in theory that these properties can be determined from the fundamental frequency (pitch); (ii) train a pitch detection model with supervision from simulated data and visual data with a physics-inspired objective; (iii) introduce a new large dataset of real pouring videos for a systematic study; (iv) show that the trained model can indeed infer these physical properties for real data; and finally, (v) we demonstrate strong generalization to various container shapes, other datasets, and in-the-wild YouTube videos. Our work presents a keen understanding of a narrow yet rich problem at the intersection of acoustics, physics, and learning. It opens up applications to enhance multisensory perception in robotic pouring. |
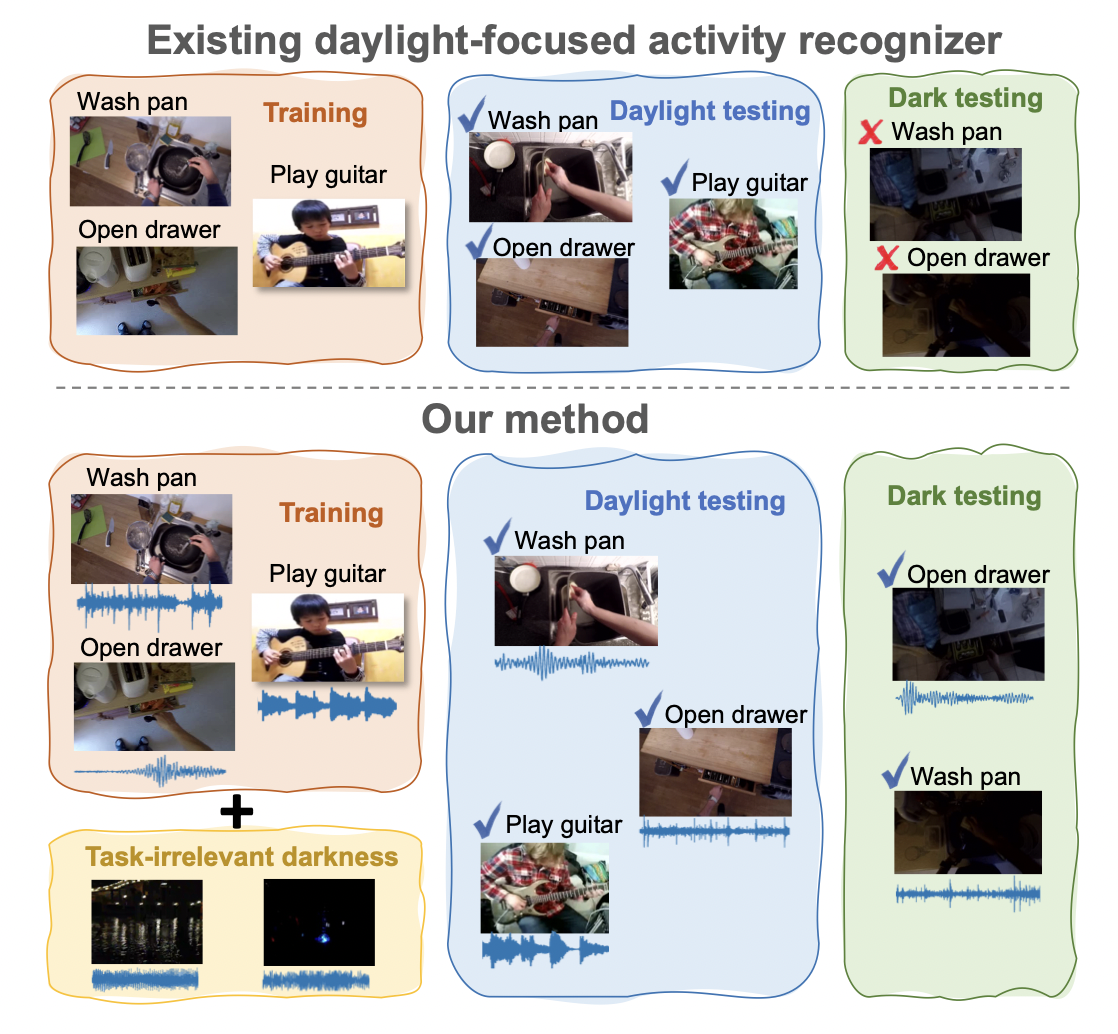 | Yunhua Zhang, Hazel Doughty, Cees G M Snoek: Day2Dark: Pseudo-Supervised Activity Recognition beyond Silent Daylight. In: International Journal of Computer Vision, vol. 133, iss. 4, pp. 2136-2157, 2025. @article{ZhangIJCV2025,
title = {Day2Dark: Pseudo-Supervised Activity Recognition beyond Silent Daylight},
author = {Yunhua Zhang and Hazel Doughty and Cees G M Snoek},
url = {https://arxiv.org/abs/2212.02053
https://link.springer.com/article/10.1007/s11263-024-02273-7},
year = {2025},
date = {2025-04-01},
urldate = {2024-11-06},
journal = {International Journal of Computer Vision},
volume = {133},
issue = {4},
pages = {2136-2157},
abstract = {This paper strives to recognize activities in the dark, as well as in the day. We first establish that state-of-the-art activity recognizers are effective during the day, but not trustworthy in the dark. The main causes are the limited availability of labeled dark videos to learn from, as well as the distribution shift towards the lower color contrast at test-time. To compensate for the lack of labeled dark videos, we introduce a pseudo-supervised learning scheme, which utilizes easy to obtain unlabeled and task-irrelevant dark videos to improve an activity recognizer in low light. As the lower color contrast results in visual information loss, we further propose to incorporate the complementary activity information within audio, which is invariant to illumination. Since the usefulness of audio and visual features differs depending on the amount of illumination, we introduce our `darkness-adaptive' audio-visual recognizer. Experiments on EPIC-Kitchens, Kinetics-Sound, and Charades demonstrate our proposals are superior to image enhancement, domain adaptation and alternative audio-visual fusion methods, and can even improve robustness to local darkness caused by occlusions. },
keywords = {},
pubstate = {published},
tppubtype = {article}
}
This paper strives to recognize activities in the dark, as well as in the day. We first establish that state-of-the-art activity recognizers are effective during the day, but not trustworthy in the dark. The main causes are the limited availability of labeled dark videos to learn from, as well as the distribution shift towards the lower color contrast at test-time. To compensate for the lack of labeled dark videos, we introduce a pseudo-supervised learning scheme, which utilizes easy to obtain unlabeled and task-irrelevant dark videos to improve an activity recognizer in low light. As the lower color contrast results in visual information loss, we further propose to incorporate the complementary activity information within audio, which is invariant to illumination. Since the usefulness of audio and visual features differs depending on the amount of illumination, we introduce our `darkness-adaptive' audio-visual recognizer. Experiments on EPIC-Kitchens, Kinetics-Sound, and Charades demonstrate our proposals are superior to image enhancement, domain adaptation and alternative audio-visual fusion methods, and can even improve robustness to local darkness caused by occlusions. |
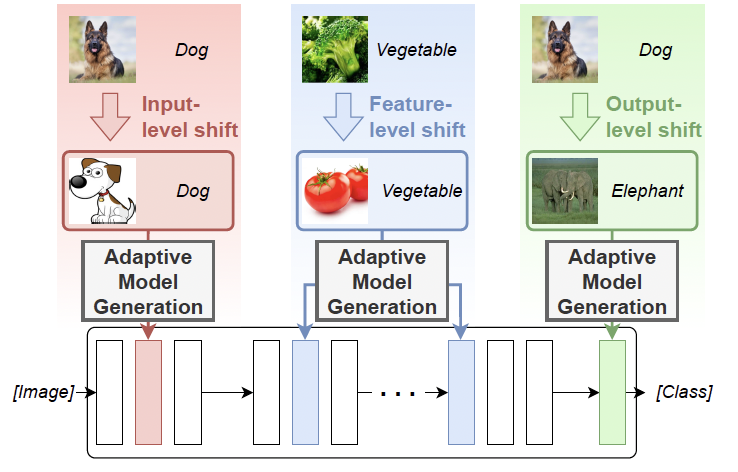 | Sameer Ambekar, Zehao Xiao, Xiantong Zhen, Cees G M Snoek: GeneralizeFormer: Layer-Adaptive Model Generation across Test-Time Distribution Shifts. In: WACV, 2025. @inproceedings{AmbekarWACV25,
title = {GeneralizeFormer: Layer-Adaptive Model Generation across Test-Time Distribution Shifts},
author = {Sameer Ambekar and Zehao Xiao and Xiantong Zhen and Cees G M Snoek},
url = {https://arxiv.org/abs/2502.12195},
year = {2025},
date = {2025-03-01},
urldate = {2025-03-01},
booktitle = {WACV},
abstract = {We consider the problem of test-time domain generalization, where a model is trained on several source domains and adjusted on target domains never seen during training. Different from the common methods that fine-tune the model or adjust the classifier parameters online, we propose to generate multiple layer parameters on the fly during inference by a lightweight meta-learned transformer, which we call GeneralizeFormer. The layer-wise parameters are generated per target batch without fine-tuning or online adjustment. By doing so, our method is more effective in dynamic scenarios with multiple target distributions and also avoids forgetting valuable source distribution characteristics. Moreover, by considering layer-wise gradients, the proposed method adapts itself to various distribution shifts. To reduce the computational and time cost, we fix the convolutional parameters while only generating parameters of the Batch Normalization layers and the linear classifier. Experiments on six widely used domain generalization datasets demonstrate the benefits and abilities of the proposed method to efficiently handle various distribution shifts, generalize in dynamic scenarios, and avoid forgetting.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
We consider the problem of test-time domain generalization, where a model is trained on several source domains and adjusted on target domains never seen during training. Different from the common methods that fine-tune the model or adjust the classifier parameters online, we propose to generate multiple layer parameters on the fly during inference by a lightweight meta-learned transformer, which we call GeneralizeFormer. The layer-wise parameters are generated per target batch without fine-tuning or online adjustment. By doing so, our method is more effective in dynamic scenarios with multiple target distributions and also avoids forgetting valuable source distribution characteristics. Moreover, by considering layer-wise gradients, the proposed method adapts itself to various distribution shifts. To reduce the computational and time cost, we fix the convolutional parameters while only generating parameters of the Batch Normalization layers and the linear classifier. Experiments on six widely used domain generalization datasets demonstrate the benefits and abilities of the proposed method to efficiently handle various distribution shifts, generalize in dynamic scenarios, and avoid forgetting. |
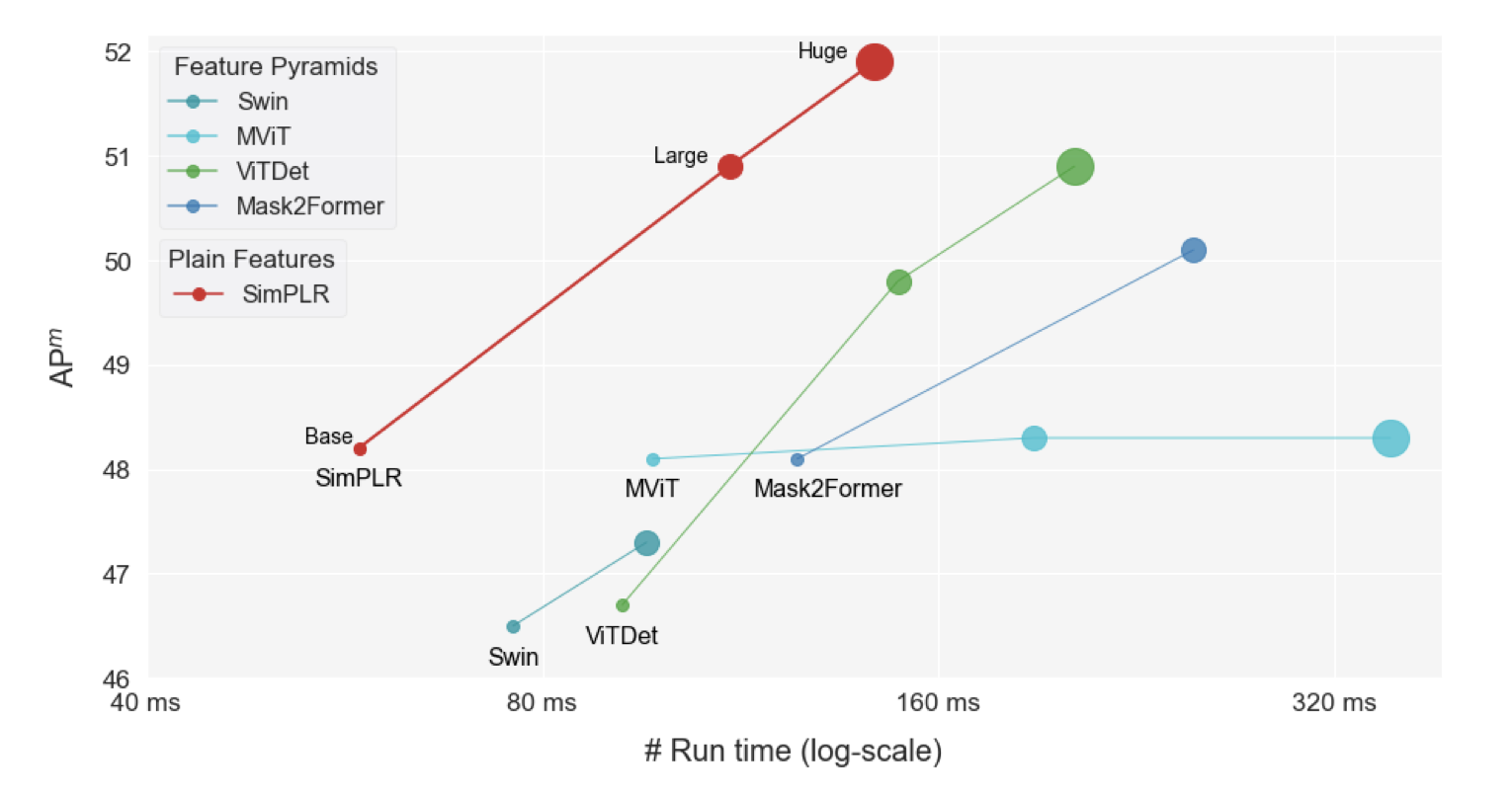 | Duy-Kien Nguyen, Martin R Oswald, Cees G M Snoek: SimPLR: A Simple and Plain Transformer for Scaling-Efficient Object Detection and Segmentation. In: Transactions on Machine Learning Research, 2025, ISSN: 2835-8856. @article{NguyenTMLR2025,
title = {SimPLR: A Simple and Plain Transformer for Scaling-Efficient Object Detection and Segmentation},
author = {Duy-Kien Nguyen and Martin R Oswald and Cees G M Snoek},
url = {https://openreview.net/forum?id=6LO1y8ZE0F
https://arxiv.org/abs/2310.05920},
issn = {2835-8856},
year = {2025},
date = {2025-02-01},
urldate = {2025-01-20},
journal = {Transactions on Machine Learning Research},
abstract = {The ability to detect objects in images at varying scales has played a pivotal role in the design of modern object detectors. Despite considerable progress in removing hand-crafted components and simplifying the architecture with transformers, multi-scale feature maps and/or pyramid design remain a key factor for their empirical success. In this paper, we show that this reliance on either feature pyramids or an hierarchical backbone is unnecessary and a transformer-based detector with scale-aware attention enables the plain detector `SimPLR' whose backbone and detection head are both non-hierarchical and operate on single-scale features. We find through our experiments that SimPLR with scale-aware attention is plain and simple, yet competitive with multi-scale vision transformer alternatives. Compared to the multi-scale and single-scale state-of-the-art, our model scales much better with bigger capacity (self-supervised) models and more pre-training data, allowing us to report a consistently better accuracy and faster runtime for object detection, instance segmentation as well as panoptic segmentation. Code will be released.},
howpublished = {arXiv:2310.05920},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
The ability to detect objects in images at varying scales has played a pivotal role in the design of modern object detectors. Despite considerable progress in removing hand-crafted components and simplifying the architecture with transformers, multi-scale feature maps and/or pyramid design remain a key factor for their empirical success. In this paper, we show that this reliance on either feature pyramids or an hierarchical backbone is unnecessary and a transformer-based detector with scale-aware attention enables the plain detector `SimPLR' whose backbone and detection head are both non-hierarchical and operate on single-scale features. We find through our experiments that SimPLR with scale-aware attention is plain and simple, yet competitive with multi-scale vision transformer alternatives. Compared to the multi-scale and single-scale state-of-the-art, our model scales much better with bigger capacity (self-supervised) models and more pre-training data, allowing us to report a consistently better accuracy and faster runtime for object detection, instance segmentation as well as panoptic segmentation. Code will be released. |
2024
|
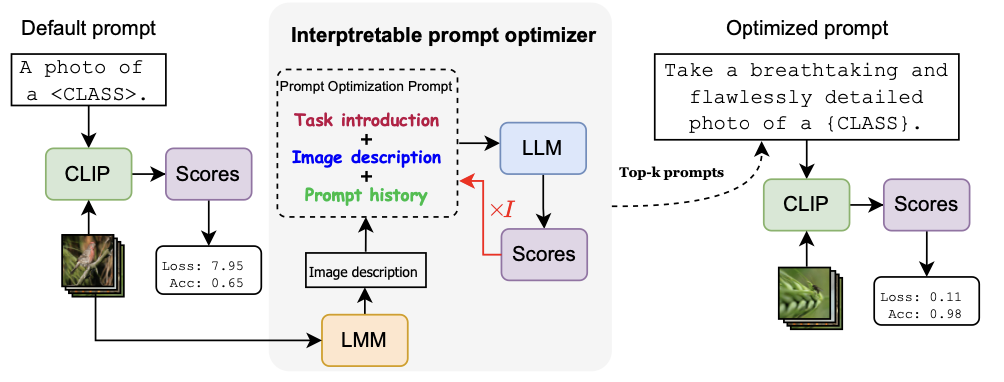 | Yingjun Du, Wenfang Sun, Cees G M Snoek: IPO: Interpretable Prompt Optimization for Vision-Language Models. In: NeurIPS, 2024. @inproceedings{DuNeurips2024,
title = {IPO: Interpretable Prompt Optimization for Vision-Language Models},
author = {Yingjun Du and Wenfang Sun and Cees G M Snoek},
url = {https://arxiv.org/abs/2410.15397
https://github.com/lmsdss/IPO},
year = {2024},
date = {2024-12-09},
urldate = {2024-12-09},
booktitle = {NeurIPS},
abstract = {Pre-trained vision-language models like CLIP have remarkably adapted to various downstream tasks. Nonetheless, their performance heavily depends on the specificity of the input text prompts, which requires skillful prompt template engineering. Instead, current approaches to prompt optimization learn the prompts through gradient descent, where the prompts are treated as adjustable parameters. However, these methods tend to lead to overfitting of the base classes seen during training and produce prompts that are no longer understandable by humans. This paper introduces a simple but interpretable prompt optimizer (IPO), that utilizes large language models (LLMs) to generate textual prompts dynamically. We introduce a Prompt Optimization Prompt that not only guides LLMs in creating effective prompts but also stores past prompts with their performance metrics, providing rich in-context information. Additionally, we incorporate a large multimodal model (LMM) to condition on visual content by generating image descriptions, which enhance the interaction between textual and visual modalities. This allows for the creation of dataset-specific prompts that improve generalization performance, while maintaining human comprehension. Extensive testing across 11 datasets reveals that IPO not only improves the accuracy of existing gradient-descent-based prompt learning methods but also considerably enhances the interpretability of the generated prompts. By leveraging the strengths of LLMs, our approach ensures that the prompts remain human-understandable, thereby facilitating better transparency and oversight for vision-language models.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Pre-trained vision-language models like CLIP have remarkably adapted to various downstream tasks. Nonetheless, their performance heavily depends on the specificity of the input text prompts, which requires skillful prompt template engineering. Instead, current approaches to prompt optimization learn the prompts through gradient descent, where the prompts are treated as adjustable parameters. However, these methods tend to lead to overfitting of the base classes seen during training and produce prompts that are no longer understandable by humans. This paper introduces a simple but interpretable prompt optimizer (IPO), that utilizes large language models (LLMs) to generate textual prompts dynamically. We introduce a Prompt Optimization Prompt that not only guides LLMs in creating effective prompts but also stores past prompts with their performance metrics, providing rich in-context information. Additionally, we incorporate a large multimodal model (LMM) to condition on visual content by generating image descriptions, which enhance the interaction between textual and visual modalities. This allows for the creation of dataset-specific prompts that improve generalization performance, while maintaining human comprehension. Extensive testing across 11 datasets reveals that IPO not only improves the accuracy of existing gradient-descent-based prompt learning methods but also considerably enhances the interpretability of the generated prompts. By leveraging the strengths of LLMs, our approach ensures that the prompts remain human-understandable, thereby facilitating better transparency and oversight for vision-language models. |
 | Mohammadreza Salehi, Nikolaos Apostolikas, Efstratios Gavves, Cees G M Snoek, Yuki M Asano: Redefining Normal: A Novel Object-Level Approach for Multi-Object Novelty Detection. In: ACCV, 2024, (Oral presentation). @inproceedings{SalehiACCV2024,
title = {Redefining Normal: A Novel Object-Level Approach for Multi-Object Novelty Detection},
author = {Mohammadreza Salehi and Nikolaos Apostolikas and Efstratios Gavves and Cees G M Snoek and Yuki M Asano},
url = {https://github.com/SMSD75/Redefining_Normal_ACCV24/tree/main
https://arxiv.org/abs/2412.11148},
year = {2024},
date = {2024-12-08},
urldate = {2024-12-08},
booktitle = {ACCV},
abstract = {In the realm of novelty detection, accurately identifying outliers in data without specific class information poses a significant challenge. While current methods excel in single-object scenarios, they struggle with multi-object situations due to their focus on individual objects. Our paper suggests a novel approach: redefining `normal' at the object level in training datasets. Rather than the usual image-level view, we consider the most dominant object in a dataset as the norm, offering a perspective that is more effective for real-world scenarios. Adapting to our object-level definition of `normal', we modify knowledge distillation frameworks, where a student network learns from a pre-trained teacher network. Our first contribution, DeFeND(Dense Feature Fine-tuning on Normal Data), integrates dense feature fine-tuning into the distillation process, allowing the teacher network to focus on object-level features with a self-supervised loss. The second is masked knowledge distillation, where the student network works with partially hidden inputs, honing its ability to deduce and generalize from incomplete data. This approach not only fares well in single-object novelty detection but also considerably surpasses existing methods in multi-object contexts.},
note = {Oral presentation},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
In the realm of novelty detection, accurately identifying outliers in data without specific class information poses a significant challenge. While current methods excel in single-object scenarios, they struggle with multi-object situations due to their focus on individual objects. Our paper suggests a novel approach: redefining `normal' at the object level in training datasets. Rather than the usual image-level view, we consider the most dominant object in a dataset as the norm, offering a perspective that is more effective for real-world scenarios. Adapting to our object-level definition of `normal', we modify knowledge distillation frameworks, where a student network learns from a pre-trained teacher network. Our first contribution, DeFeND(Dense Feature Fine-tuning on Normal Data), integrates dense feature fine-tuning into the distillation process, allowing the teacher network to focus on object-level features with a self-supervised loss. The second is masked knowledge distillation, where the student network works with partially hidden inputs, honing its ability to deduce and generalize from incomplete data. This approach not only fares well in single-object novelty detection but also considerably surpasses existing methods in multi-object contexts. |
 | Aozhu Chen, Hazel Doughty, Xirong Li, Cees G M Snoek: Beyond Coarse-Grained Matching in Video-Text Retrieval. In: ACCV, 2024, (Oral presentation). @inproceedings{ChenACCV2024,
title = {Beyond Coarse-Grained Matching in Video-Text Retrieval},
author = {Aozhu Chen and Hazel Doughty and Xirong Li and Cees G M Snoek},
url = {https://arxiv.org/abs/2410.12407},
year = {2024},
date = {2024-12-08},
urldate = {2024-12-08},
booktitle = {ACCV},
abstract = {Video-text retrieval has seen significant advancements, yet the ability of models to discern subtle differences in captions still requires verification. In this paper, we introduce a new approach for fine-grained evaluation. Our approach can be applied to existing datasets by automatically generating hard negative test captions with subtle single-word variations across nouns, verbs, adjectives, adverbs, and prepositions. We perform comprehensive experiments using four state-of-the-art models across two standard benchmarks (MSR-VTT and VATEX) and two specially curated datasets enriched with detailed descriptions (VLN-UVO and VLN-OOPS), resulting in a number of novel insights: 1) our analyses show that the current evaluation benchmarks fall short in detecting a model's ability to perceive subtle single-word differences, 2) our fine-grained evaluation highlights the difficulty models face in distinguishing such subtle variations. To enhance fine-grained understanding, we propose a new baseline that can be easily combined with current methods. Experiments on our fine-grained evaluations demonstrate that this approach enhances a model's ability to understand fine-grained differences.},
note = {Oral presentation},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Video-text retrieval has seen significant advancements, yet the ability of models to discern subtle differences in captions still requires verification. In this paper, we introduce a new approach for fine-grained evaluation. Our approach can be applied to existing datasets by automatically generating hard negative test captions with subtle single-word variations across nouns, verbs, adjectives, adverbs, and prepositions. We perform comprehensive experiments using four state-of-the-art models across two standard benchmarks (MSR-VTT and VATEX) and two specially curated datasets enriched with detailed descriptions (VLN-UVO and VLN-OOPS), resulting in a number of novel insights: 1) our analyses show that the current evaluation benchmarks fall short in detecting a model's ability to perceive subtle single-word differences, 2) our fine-grained evaluation highlights the difficulty models face in distinguishing such subtle variations. To enhance fine-grained understanding, we propose a new baseline that can be easily combined with current methods. Experiments on our fine-grained evaluations demonstrate that this approach enhances a model's ability to understand fine-grained differences. |
 | Hazel Doughty, Fida Mohammad Thoker, Cees G M Snoek: LocoMotion: Learning Motion-Focused Video-Language Representations. In: ACCV, 2024, (Oral presentation). @inproceedings{DoughtyACCV2024,
title = {LocoMotion: Learning Motion-Focused Video-Language Representations},
author = {Hazel Doughty and Fida Mohammad Thoker and Cees G M Snoek},
url = {https://hazeldoughty.github.io/Papers/LocoMotion/
https://arxiv.org/abs/2410.12018},
year = {2024},
date = {2024-12-08},
urldate = {2024-12-08},
booktitle = {ACCV},
abstract = {This paper strives for motion-focused video-language representations. Existing methods to learn video-language representations use spatial-focused data, where identifying the objects and scene is often enough to distinguish the relevant caption. We instead propose LocoMotion to learn from motion-focused captions that describe the movement and temporal progression of local object motions. We achieve this by adding synthetic motions to videos and using the parameters of these motions to generate corresponding captions. Furthermore, we propose verb-variation paraphrasing to increase the caption variety and learn the link between primitive motions and high-level verbs. With this, we are able to learn a motion-focused video-language representation. Experiments demonstrate our approach is effective for a variety of downstream tasks, particularly when limited data is available for fine-tuning.},
note = {Oral presentation},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
This paper strives for motion-focused video-language representations. Existing methods to learn video-language representations use spatial-focused data, where identifying the objects and scene is often enough to distinguish the relevant caption. We instead propose LocoMotion to learn from motion-focused captions that describe the movement and temporal progression of local object motions. We achieve this by adding synthetic motions to videos and using the parameters of these motions to generate corresponding captions. Furthermore, we propose verb-variation paraphrasing to increase the caption variety and learn the link between primitive motions and high-level verbs. With this, we are able to learn a motion-focused video-language representation. Experiments demonstrate our approach is effective for a variety of downstream tasks, particularly when limited data is available for fine-tuning. |
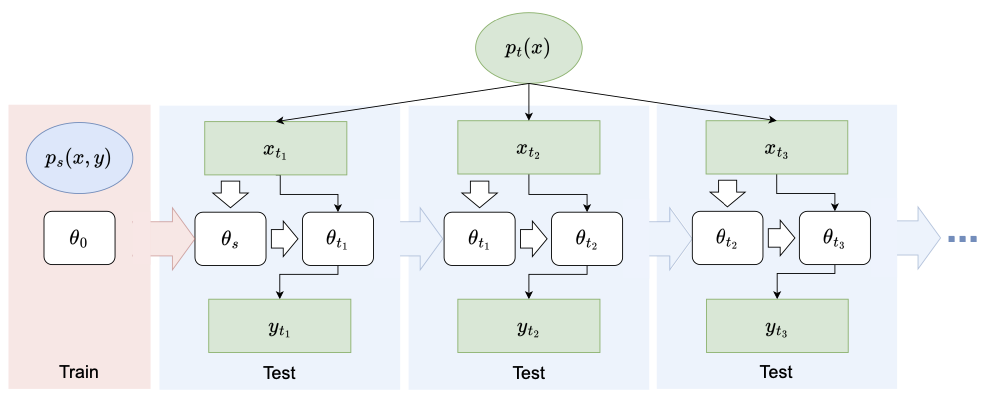 | Zehao Xiao, Cees G M Snoek: Beyond Model Adaptation at Test Time: A Survey. arXiv:2411.03687, 2024. @unpublished{XiaoArxiv2024,
title = {Beyond Model Adaptation at Test Time: A Survey},
author = {Zehao Xiao and Cees G M Snoek},
url = {https://arxiv.org/abs/2411.03687
https://github.com/zzzx1224/Beyond-model-adaptation-at-test-time-Papers},
year = {2024},
date = {2024-11-06},
urldate = {2024-11-06},
abstract = {Machine learning algorithms have achieved remarkable success across various disciplines, use cases and applications, under the prevailing assumption that training and test samples are drawn from the same distribution. Consequently, these algorithms struggle and become brittle even when samples in the test distribution start to deviate from the ones observed during training. Domain adaptation and domain generalization have been studied extensively as approaches to address distribution shifts across test and train domains, but each has its limitations. Test-time adaptation, a recently emerging learning paradigm, combines the benefits of domain adaptation and domain generalization by training models only on source data and adapting them to target data during test-time inference. In this survey, we provide a comprehensive and systematic review on test-time adaptation, covering more than 400 recent papers. We structure our review by categorizing existing methods into five distinct categories based on what component of the method is adjusted for test-time adaptation: the model, the inference, the normalization, the sample, or the prompt, providing detailed analysis of each. We further discuss the various preparation and adaptation settings for methods within these categories, offering deeper insights into the effective deployment for the evaluation of distribution shifts and their real-world application in understanding images, video and 3D, as well as modalities beyond vision. We close the survey with an outlook on emerging research opportunities for test-time adaptation.},
howpublished = {arXiv:2411.03687},
keywords = {},
pubstate = {published},
tppubtype = {unpublished}
}
Machine learning algorithms have achieved remarkable success across various disciplines, use cases and applications, under the prevailing assumption that training and test samples are drawn from the same distribution. Consequently, these algorithms struggle and become brittle even when samples in the test distribution start to deviate from the ones observed during training. Domain adaptation and domain generalization have been studied extensively as approaches to address distribution shifts across test and train domains, but each has its limitations. Test-time adaptation, a recently emerging learning paradigm, combines the benefits of domain adaptation and domain generalization by training models only on source data and adapting them to target data during test-time inference. In this survey, we provide a comprehensive and systematic review on test-time adaptation, covering more than 400 recent papers. We structure our review by categorizing existing methods into five distinct categories based on what component of the method is adjusted for test-time adaptation: the model, the inference, the normalization, the sample, or the prompt, providing detailed analysis of each. We further discuss the various preparation and adaptation settings for methods within these categories, offering deeper insights into the effective deployment for the evaluation of distribution shifts and their real-world application in understanding images, video and 3D, as well as modalities beyond vision. We close the survey with an outlook on emerging research opportunities for test-time adaptation. |
