
The ICML 2020 paper Learning to Learn Kernels with Variational Random Features by Xiantong Zhen, Haoliang Sun, Yingjun Du, Jun Xu, Yilong Yin, Ling Shaoand Cees Snoek is now available. In this work, we introduce kernels with random Fourier features in the meta-learning framework to leverage their strong few-shot learning ability. We propose meta variational random features (MetaVRF) to learn adaptive kernels for the base-learner, which is developed in a latent variable model by treating the random feature basis as the latent variable. We formulate the optimization of MetaVRF as a variational inference problem by deriving an evidence lower bound under the meta-learning framework. To incorporate shared knowledge from related tasks, we propose a context inference of the posterior, which is established by an LSTM architecture. The LSTM-based inference network can effectively integrate the context information of previous tasks with task-specific information, generating informative and adaptive features. The learned MetaVRF can produce kernels of high representational power with a relatively low spectral sampling rate and also enables fast adaptation to new tasks. Experimental results on a variety of few-shot regression and classification tasks demonstrate that MetaVRF delivers much better, or at least competitive, performance compared to existing meta-learning alternatives.



 The CVPR 2019 paper Spherical Regression: Learning Viewpoints, Surface Normals and 3D Rotations on n-Spheres by Shuai Liao,
The CVPR 2019 paper Spherical Regression: Learning Viewpoints, Surface Normals and 3D Rotations on n-Spheres by Shuai Liao,  The CVPR 2019 paper Dance with Flow: Two-in-One Stream Action Detection by
The CVPR 2019 paper Dance with Flow: Two-in-One Stream Action Detection by 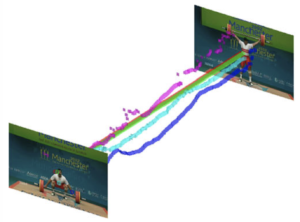 The paper “Pointly-Supervised Action Localization” by Pascal Mettes and Cees Snoek has been published in the International Journal of Computer Vision.
The paper “Pointly-Supervised Action Localization” by Pascal Mettes and Cees Snoek has been published in the International Journal of Computer Vision. 