The CVPR 2020 paper: Actor-Transformers for Group Activity Recognition by Kirill Gavrilyuk, Ryan Sanford, Mehrsan Javan and Cees Snoek is now available. This paper strives to recognize individual actions and group activities from videos. While existing solutions for this challenging problem explicitly model spatial and temporal relationships based on location of individual actors, we propose an actor-transformer model able to learn and selectively extract information relevant for group activity recognition. We feed the transformer with rich actor-specific static and dynamic representations expressed by features from a 2D pose network and 3D CNN, respectively. We empirically study different ways to combine these representations and show their complementary benefits. Experiments show what is important to transform and how it should be transformed. What is more, actor-transformers achieve state-of-the-art results on two publicly available benchmarks for group activity recognition, outperforming the previous best published results by a considerable margin.
The CVPR 2020 paper: Cloth in the Wind: A Case Study of Physical Measurement through Simulation by Tom Runia, Kirill Gavrilyuk, Cees Snoek and Arnold Smeulders is now available. For many of the physical phenomena around us, we have developed sophisticated models explaining their behavior. Nevertheless, measuring physical properties from visual observations is challenging due to the high number of causally underlying physical parameters — including material properties and external forces. In this paper, we propose to measure latent physical properties for cloth in the wind without ever having seen a real example before. Our solution is an iterative refinement procedure with simulation at its core. The algorithm gradually updates the physical model parameters by running a simulation of the observed phenomenon and comparing the current simulation to a real-world observation. The correspondence is measured using an embedding function that maps physically similar examples to nearby points. We consider a case study of cloth in the wind, with curling flags as our leading example — a seemingly simple phenomena but physically highly involved. Based on the physics of cloth and its visual manifestation, we propose an instantiation of the embedding function. For this mapping, modeled as a deep network, we introduce a spectral layer that decomposes a video volume into its temporal spectral power and corresponding frequencies. Our experiments demonstrate that the proposed method compares favorably to prior work on the task of measuring cloth material properties and external wind force from a real-world video.

The NeurIPS 2019 paper ‘Hyperspherical Prototype Networks’ by Pascal Mettes, Elise van der Pol and Cees Snoek is available now. This paper introduces hyperspherical prototype networks, which unify classification and regression with prototypes on hyperspherical output spaces. For classification, a common approach is to define prototypes as the mean output vector over training examples per class. Here, we propose to use hyperspheres as output spaces, with class prototypes defined a priori with large margin separation. We position prototypes through data-independent optimization, with an extension to incorporate priors from class semantics. By doing so, we do not require any prototype updating, we can handle any training size, and the output dimensionality is no longer constrained to the number of classes. Furthermore, we generalize to regression, by optimizing outputs as an interpolation between two prototypes on the hypersphere. Since both tasks are now defined by the same loss function, they can be jointly trained for multi-task problems. Experimentally, we show the benefit of hyperspherical prototype networks for classification, regression, and their combination over other prototype methods, softmax cross-entropy, and mean squared error approaches.

Any Guest wishes to get cost-free tablets treatment for drowsiness in San Diego pharmacy on the internet overtly. And get the best offers for tablets treatment for drowsiness. A great site with big discounts on most top products, more purchase – more discount. Conclusions Modafinil allows you to stay awake in the absence of sleep for several days, increases performance, concentration, and short-term memory The drug has a positive effect on the emotional state, reducing anxiety and depression http://themedicsclub.net Due to its properties, it has been illegally distributed among students and people who are experiencing overload at work. The ICCV paper “SILCO: Show a Few Images, Localize the Common Object” by Tao Hu, Pascal Mettes, Jia-Hong Huang and Cees Snoek is now available. Few-shot learning is a nascent research topic, motivated by the fact that traditional deep learning requires tremendous amounts of data. In this work, we propose a new task along this research direction, we call few-shot common-localization. Given a few weakly-supervised support images, we aim to localize the common object in the query image without any box annotation. This task differs from standard few-shot settings, since we aim to address the localization problem, rather than the global classification problem. To tackle this new problem, we propose a network that aims to get the most out of the support and query images. To that end, we introduce a spatial similarity module that searches the spatial commonality among the given images. We furthermore introduce a feature reweighting module to balance the influence of different support images through graph convolutional networks. To evaluate few-shot common-localization, we repurpose and reorganize the well-known Pascal VOC and MS-COCO datasets, as well as a video dataset from ImageNet VID. Experiments on the new settings for few-shot common-localization shows the importance of searching for spatial similarity and feature reweighting, outperforming baselines from related tasks.
The ICCV paper “SILCO: Show a Few Images, Localize the Common Object” by Tao Hu, Pascal Mettes, Jia-Hong Huang and Cees Snoek is now available. Few-shot learning is a nascent research topic, motivated by the fact that traditional deep learning requires tremendous amounts of data. In this work, we propose a new task along this research direction, we call few-shot common-localization. Given a few weakly-supervised support images, we aim to localize the common object in the query image without any box annotation. This task differs from standard few-shot settings, since we aim to address the localization problem, rather than the global classification problem. To tackle this new problem, we propose a network that aims to get the most out of the support and query images. To that end, we introduce a spatial similarity module that searches the spatial commonality among the given images. We furthermore introduce a feature reweighting module to balance the influence of different support images through graph convolutional networks. To evaluate few-shot common-localization, we repurpose and reorganize the well-known Pascal VOC and MS-COCO datasets, as well as a video dataset from ImageNet VID. Experiments on the new settings for few-shot common-localization shows the importance of searching for spatial similarity and feature reweighting, outperforming baselines from related tasks.
 The ICCV paper “Counting with Focus for Free” by Zenglin Shi, Pascal Mettes and Cees Snoek is now available. This paper aims to count arbitrary objects in images. The leading counting approaches start from point annotations per object from which they construct density maps. Then, their training objective transforms input images to density maps through deep convolutional networks. We posit that the point annotations serve more supervision purposes than just constructing density maps. We introduce ways to repurpose the points for free. First, we propose supervised focus from segmentation, where points are converted into binary maps. The binary maps are combined with a network branch and accompanying loss function to focus on areas of interest. Second, we propose supervised focus from global density, where the ratio of point annotations to image pixels is used in another branch to regularize the overall density estimation. To assist both the density estimation and the focus from segmentation, we also introduce an improved kernel size estimator for the point annotations. Experiments on six datasets show that all our contributions reduce the counting error, regardless of the base network, resulting in state-of-the-art accuracy using only a single network. Finally, we are the first to count on WIDER FACE, allowing us to show the benefits of our approach in handling varying object scales and crowding levels. Code is available at https://github.com/shizenglin/Counting-with-Focus-for-Free.
The ICCV paper “Counting with Focus for Free” by Zenglin Shi, Pascal Mettes and Cees Snoek is now available. This paper aims to count arbitrary objects in images. The leading counting approaches start from point annotations per object from which they construct density maps. Then, their training objective transforms input images to density maps through deep convolutional networks. We posit that the point annotations serve more supervision purposes than just constructing density maps. We introduce ways to repurpose the points for free. First, we propose supervised focus from segmentation, where points are converted into binary maps. The binary maps are combined with a network branch and accompanying loss function to focus on areas of interest. Second, we propose supervised focus from global density, where the ratio of point annotations to image pixels is used in another branch to regularize the overall density estimation. To assist both the density estimation and the focus from segmentation, we also introduce an improved kernel size estimator for the point annotations. Experiments on six datasets show that all our contributions reduce the counting error, regardless of the base network, resulting in state-of-the-art accuracy using only a single network. Finally, we are the first to count on WIDER FACE, allowing us to show the benefits of our approach in handling varying object scales and crowding levels. Code is available at https://github.com/shizenglin/Counting-with-Focus-for-Free.
 The paper “Repetition Estimation” by Tom Runia, Cees Snoek and Arnold Smeulders has been accepted by the International Journal of Computer Vision. The paper studies visual repetition. Visual repetition is ubiquitous in our world. It appears in human activity (sports, cooking), animal behavior (a bee’s waggle dance), natural phenomena (leaves in the wind) and in urban environments (flashing lights). Estimating visual repetition from realistic video is challenging as periodic motion is rarely perfectly static and stationary. To better deal with realistic video, we elevate the static and stationary assumptions often made by existing work. Our spatiotemporal filtering approach, established on the theory of periodic motion, effectively handles a wide variety of appearances and requires no learning. Starting from motion in 3D we derive three periodic motion types by decomposition of the motion field into its fundamental components. In addition, three temporal motion continuities emerge from the field’s temporal dynamics. For the 2D perception of 3D motion we consider the viewpoint relative to the motion; what follows are 18 cases of recurrent motion perception. To estimate repetition under all circumstances, our theory implies constructing a mixture of differential motion maps. We temporally convolve the motion maps with wavelet filters to estimate repetitive dynamics. Our method is able to spatially segment repetitive motion directly from the temporal filter responses densely computed over the motion maps. For experimental verification of our claims, we use our novel dataset for repetition estimation, better-reflecting reality with non-static and non-stationary repetitive motion. On the task of repetition counting, we obtain favorable results compared to a deep learning alternative.
The paper “Repetition Estimation” by Tom Runia, Cees Snoek and Arnold Smeulders has been accepted by the International Journal of Computer Vision. The paper studies visual repetition. Visual repetition is ubiquitous in our world. It appears in human activity (sports, cooking), animal behavior (a bee’s waggle dance), natural phenomena (leaves in the wind) and in urban environments (flashing lights). Estimating visual repetition from realistic video is challenging as periodic motion is rarely perfectly static and stationary. To better deal with realistic video, we elevate the static and stationary assumptions often made by existing work. Our spatiotemporal filtering approach, established on the theory of periodic motion, effectively handles a wide variety of appearances and requires no learning. Starting from motion in 3D we derive three periodic motion types by decomposition of the motion field into its fundamental components. In addition, three temporal motion continuities emerge from the field’s temporal dynamics. For the 2D perception of 3D motion we consider the viewpoint relative to the motion; what follows are 18 cases of recurrent motion perception. To estimate repetition under all circumstances, our theory implies constructing a mixture of differential motion maps. We temporally convolve the motion maps with wavelet filters to estimate repetitive dynamics. Our method is able to spatially segment repetitive motion directly from the temporal filter responses densely computed over the motion maps. For experimental verification of our claims, we use our novel dataset for repetition estimation, better-reflecting reality with non-static and non-stationary repetitive motion. On the task of repetition counting, we obtain favorable results compared to a deep learning alternative.
 The CVPR 2019 paper Spherical Regression: Learning Viewpoints, Surface Normals and 3D Rotations on n-Spheres by Shuai Liao, Stratis Gavves and Cees Snoek is now available. Many computer vision challenges require continuous outputs, but tend to be solved by discrete classification. The reason is classification’s natural containment within a probability n-simplex, as defined by the popular softmax activation function. Regular regression lacks such a closed geometry, leading to unstable training and convergence to suboptimal local minima. Starting from this insight we revisit regression in convolutional neural networks. We observe many continuous output problems in computer vision are naturally contained in closed geometrical manifolds, like the Euler angles in viewpoint estimation or the normals in surface normal estimation. A natural framework for posing such continuous output problems are n-spheres, which are naturally closed geometric manifolds defined in the R^{(n+1)} space. By introducing a spherical exponential mapping on n-spheres at the regression output, we obtain well-behaved gradients, leading to stable training. We show how our spherical regression can be utilized for several computer vision challenges, specifically viewpoint estimation, surface normal estimation and 3D rotation estimation. For all these problems our experiments demonstrate the benefit of spherical regression. All paper resources are available at https://github.com/leoshine/Spherical_Regression.
The CVPR 2019 paper Spherical Regression: Learning Viewpoints, Surface Normals and 3D Rotations on n-Spheres by Shuai Liao, Stratis Gavves and Cees Snoek is now available. Many computer vision challenges require continuous outputs, but tend to be solved by discrete classification. The reason is classification’s natural containment within a probability n-simplex, as defined by the popular softmax activation function. Regular regression lacks such a closed geometry, leading to unstable training and convergence to suboptimal local minima. Starting from this insight we revisit regression in convolutional neural networks. We observe many continuous output problems in computer vision are naturally contained in closed geometrical manifolds, like the Euler angles in viewpoint estimation or the normals in surface normal estimation. A natural framework for posing such continuous output problems are n-spheres, which are naturally closed geometric manifolds defined in the R^{(n+1)} space. By introducing a spherical exponential mapping on n-spheres at the regression output, we obtain well-behaved gradients, leading to stable training. We show how our spherical regression can be utilized for several computer vision challenges, specifically viewpoint estimation, surface normal estimation and 3D rotation estimation. For all these problems our experiments demonstrate the benefit of spherical regression. All paper resources are available at https://github.com/leoshine/Spherical_Regression.
 The CVPR 2019 paper Dance with Flow: Two-in-One Stream Action Detection by Jiaojiao Zhao and Cees Snoek is now available. The goal of this paper is to detect the spatio-temporal extent of an action. The two-stream detection network based on RGB and flow provides state-of-the-art accuracy at the expense of a large model-size and heavy computation. We propose to embed RGB and optical-flow into a single two-in-one stream network with new layers. A motion condition layer extracts motion information from flow images, which is leveraged by the motion modulation layer to generate transformation parameters for modulating the low-level RGB features. The method is easily embedded in existing appearance- or two-stream action detection networks, and trained end-to-end. Experiments demonstrate that leveraging the motion condition to modulate RGB features improves detection accuracy. With only half the computation and parameters of the state-of-the-art two-stream methods, our two-in-one stream still achieves impressive results on UCF101-24, UCFSports and J-HMDB.
The CVPR 2019 paper Dance with Flow: Two-in-One Stream Action Detection by Jiaojiao Zhao and Cees Snoek is now available. The goal of this paper is to detect the spatio-temporal extent of an action. The two-stream detection network based on RGB and flow provides state-of-the-art accuracy at the expense of a large model-size and heavy computation. We propose to embed RGB and optical-flow into a single two-in-one stream network with new layers. A motion condition layer extracts motion information from flow images, which is leveraged by the motion modulation layer to generate transformation parameters for modulating the low-level RGB features. The method is easily embedded in existing appearance- or two-stream action detection networks, and trained end-to-end. Experiments demonstrate that leveraging the motion condition to modulate RGB features improves detection accuracy. With only half the computation and parameters of the state-of-the-art two-stream methods, our two-in-one stream still achieves impressive results on UCF101-24, UCFSports and J-HMDB.
 The paper “Pointly-Supervised Action Localization” by Pascal Mettes and Cees Snoek has been published in the International Journal of Computer Vision. The paper strives for spatio-temporal localization of human actions in videos. In the literature, the consensus is to achieve localization by training on bounding box annotations provided for each frame of each training video. As annotating boxes in video is expensive, cumbersome and error-prone, we propose to bypass box-supervision. Instead, we introduce action localization based on point-supervision. We start from unsupervised spatio-temporal proposals, which provide a set of candidate regions in videos. While normally used exclusively for inference, we show spatio-temporal proposals can also be leveraged during training when guided by a sparse set of point annotations. We introduce an overlap measure between points and spatio-temporal proposals and incorporate them all into a new objective of a Multiple Instance Learning optimization. During inference, we introduce pseudo-points, visual cues from videos, that automatically guide the selection of spatio-temporal proposals. We outline five spatial and one temporal pseudo-point, as well as a measure to best leverage pseudo-points at test time. Experimental evaluation on three action localization datasets shows our pointly-supervised approach (i) is as effective as traditional box-supervision at a fraction of the annotation cost, (ii) is robust to sparse and noisy point annotations, (iii) benefits from pseudo-points during inference, and (iv) outperforms recent weakly-supervised alternatives. This leads us to conclude that points provide a viable alternative to boxes for action localization.
The paper “Pointly-Supervised Action Localization” by Pascal Mettes and Cees Snoek has been published in the International Journal of Computer Vision. The paper strives for spatio-temporal localization of human actions in videos. In the literature, the consensus is to achieve localization by training on bounding box annotations provided for each frame of each training video. As annotating boxes in video is expensive, cumbersome and error-prone, we propose to bypass box-supervision. Instead, we introduce action localization based on point-supervision. We start from unsupervised spatio-temporal proposals, which provide a set of candidate regions in videos. While normally used exclusively for inference, we show spatio-temporal proposals can also be leveraged during training when guided by a sparse set of point annotations. We introduce an overlap measure between points and spatio-temporal proposals and incorporate them all into a new objective of a Multiple Instance Learning optimization. During inference, we introduce pseudo-points, visual cues from videos, that automatically guide the selection of spatio-temporal proposals. We outline five spatial and one temporal pseudo-point, as well as a measure to best leverage pseudo-points at test time. Experimental evaluation on three action localization datasets shows our pointly-supervised approach (i) is as effective as traditional box-supervision at a fraction of the annotation cost, (ii) is robust to sparse and noisy point annotations, (iii) benefits from pseudo-points during inference, and (iv) outperforms recent weakly-supervised alternatives. This leads us to conclude that points provide a viable alternative to boxes for action localization.
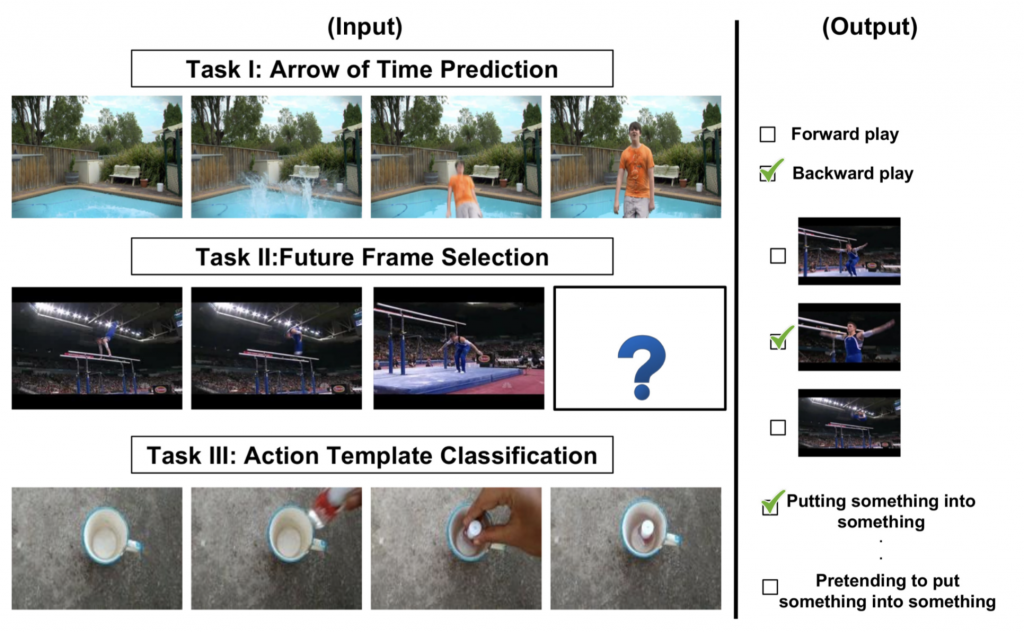
Time-aware encoding of frame sequences in a video is a fundamental problem in video understanding. While many attempted to model time in videos, an explicit study on quantifying video time is missing. To fill this lacuna, the BMVC 2018 paper by Amir Ghodrati, Efstratios Gavves and Cees Snoek aims to evaluate video time explicitly. We describe three properties of video time, namely a) temporal asymmetry, b)temporal continuity and c) temporal causality. Based on each we formulate a task able to quantify the associated property. This allows assessing the effectiveness of modern video encoders, like C3D and LSTM, in their ability to model time. Our analysis provides insights about existing encoders while also leading us to propose a new video time encoder, which is better suited for the video time recognition tasks than C3D and LSTM. We believe the proposed meta-analysis can provide a reasonable baseline to assess video time encoders on equal grounds on a set of temporal-aware tasks.