
UvA-Euvision Team Presents at ImageNet Workshop
Amidst fierce competition the UvA-Euvision team participated in the new ImageNet object detection task where the goal is to tell what object is in an image and where it is located. The organizers defined 200 basic-level categories for this task (e.g. accordion, airplane, ant, antelope and apple) . The categories were carefully chosen considering different factors such as object scale, level of image clutterness, average number of object instance, and several others.
The number of categories won by the University of Amsterdam – Euvision Technologies team is 130, out of 200.
The purpose of the workshop is to present the methods and results of the Image Net Large Scale Visual Recognition Challenge (ILSVRC) 2013. Challenge participants with the most successful and innovative entries are invited to present, and the UvA-Euvision team is amongst them.
The ImageNet 2013 Detection Task
To summarize our participation, for task 1, the ILSVRC2013 detection task on 200 classes, we submit two runs. Our runs utilize a new way of efficient encoding. The method is currently under submission, therefore we can not include identifying details on this part. The submission utilizes selective search (Uijlings et al. IJCV 2013) to create on many candidate boxes per image. These boxes are represented by extracting densely sampled color SIFT descriptors (van de Sande et al, PAMI 2010) at multiple scales. The box is then encoded with our new efficient coding. The method is faster than bag-of-words with hard assignment and outperforms it in terms of accuracy. Each box is encoded with a multi-level spatial pyramid. Training follows a standard negative mining procedure based on the previous work. The first run is context-free. The 200 models are trained independently of one another. The second run utilizes a convolutional network, trained on the DET dataset, to compute a prior for the presence of an object in the image.
The ImageNet 2013 Classification Task
For task 2, the ILSVRC2013 classification task on 1,000 classes, we submit two runs.Our showcase run performs all evaluations of the test set on an iPhone 5s at a rate of 2 images per second, whereas on the iPhone 4 it has a performance of 1 image per 10 seconds. The results in the main run are based on the fusion of convolutional networks. The networks are compatible to the networks that won this task last year (Krizhevsky et al, NIPS 2012), where our networks have 76M free parameters. The parameters have been trained for 300 epochs on a single GPU. For training in both runs we have used the ImageNet 1,000 dataset. No (pre-)training on other datasets has been performed.
Demo on iPhone Available
At the ILSVRC2013 workshop we will release an app in the App Store performing instant interactive photo classification (take a picture, see the top 5 ImageNet scores). This app uses the same engine as our Impala app that is already available at: https://itunes.apple.com/us/app/impala/id736620048 . The Impala app user interface was designed for the experience that the iPhone works for you, but can still be optimized. The current results reflect the match of the training data with the personal data on the iPhone.
December 7 in Sydney, Australia
The ImageNet workshop is held December 7 in Sydney. The workshop is organized in conjunction with the International Conference on Computer Vision.



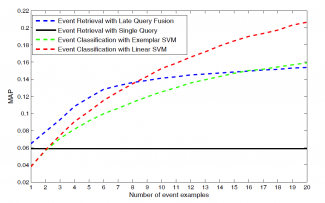 The ACM Multimedia’13 paper on “Querying for Video Events by Semantic Signatures from Few Examples” by Masoud Mazloom, Amirhossein Habibian and Cees Snoek is
The ACM Multimedia’13 paper on “Querying for Video Events by Semantic Signatures from Few Examples” by Masoud Mazloom, Amirhossein Habibian and Cees Snoek is 


